В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны! Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна. Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
LLaMA 3 вышла! Увы, только в размерах 8B и 70B. Промты уже вшиты в новую таверну, ждём исправлений по части квантования от жоры, наверняка он подгадил.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт). Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной. В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090. Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой: 1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии. 2. Скачиваем модель в gguf формате. Например вот эту: https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt 3. Запускаем koboldcpp.exe и выбираем скачанную модель. 4. Заходим в браузере на http://localhost:5001/ 5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI 1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern 2. Запускаем всё добро 3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001 4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca 5. Радуемся
Я посмотрел на сайте Mistral AI - что-то вообще нет упоминаний о модели 70В. Только 7В и Микстрали. Они что, вообще решили отказаться от семидесятки или собираются её продавать?
>>718008 >мини-моделей Да ёб ты нахуй. >>718018 >Они что, вообще решили отказаться от семидесятки Они никогда не заявляли её наличие. Усё, их купили, всё закрыто. >>718027 Если нужно что-то серьёзное, то только закрытые. Остальное ты плюс минус перечислил.
>>717920 → А вот это прикольно. Все больше смыслов не писать свои обработчики, а юзать таверну.
———
Так, я че-то охуел. Вы че хуйню советуете? 1. Берешь лламу.цпп там есть куча вариков запуска. 2. Пишешь на JS оформление запроса с промптом + посылание в лламу.цпп 3. Пишешь хтмл-чат. Буквально все, там вообще найух не нужно ничего кроме голой лламы.цпп, в чем проблема вообще, я в ахуе.
>>717974 → > Да даже банально им будет интересно окунуться в ллм если раньше не пробовали и начнут с использования. Согласен. Никогда не считал себя гением, и если у слесаря-пенсионера хватает мозгов поднимать ллмки, то уж студенты как-нибудь разберутся. Щас бы JS-чат написать невмочь на готовом сервере.
>>717979 → А кто вообще автор вопроса и что ему надо? А то тут все обсуждают, а я не уловил, откуда инфа про студентов-кумеров и отсутствие контекста. =D
>>718027 Тебе врут, их куча, но запустить ты сможешь только хуйню, живи с этим. =) Есть CogAgent, пиздатый. Есть че-то еще, но я забил даже на названия. LLaVa-1.6 в принципе неплоха, стоит остановиться на ней, на самом деле. Все остальные старички типа Qwen-VL и прочих слабы, поэтому не стоят внимания. ИМХО — или Ког, или Ллава-1.6, два варика.
>>717981 → > так как системный промт будет общим Оно будет оставаться в кэшэ т.к. все запросы начинаются одинаково, но это всеравно крохи. В случае нескольких бэков на малой нагрузке можно сделать привязку юзера к гпу в формате filo, тогда количество обработок чуть сократится, но это почти ситуация простоя оборудования. Использовать кобольд да и жору в принципе для подобных задач, где обработка немаленького контекста может быть почти на каждый запрос - не оптимальное решение. >>717988 → Какое такое? Разборка латиносов всех гендеров и возрастов - норм, регулярные битвы китайских тоддеров и грузовиков со стабильным исходом - норм, извинения перед дедпулом - норм, еот треды - норм, а тут рофловая карточка - вах какой ужас? Главное, не пытайся представить какие мыслепреступления технически возможно совершить, в обморок упадешь. Все это лицемерная хуета и попытки манипулировать, а все ради лоббистов-корпоратов, которым глубоко насрать на все то "хорошее", которое используют в качестве предлогов. >>718056 > Вы че хуйню советуете? > 1. Берешь лламу.цпп На ноль поделил с порога > кто вообще автор вопроса >>717906 →
Здесь был чел который трейнил модели. Если ты тут, подскажи вот такую вещь: допустим в json в каждом примере (т.е. имею в виду объекты внутри { }), для простоты в форм. альпаки, длина каждой строки (инпут инстракт ...) пусть 4к, при трейне лоры ставишь обрезку например 2048. Так вот до этих 2048 будет обрезяться каждая строка внутри примера или же весь пример? т.е. длина куска относится к примеру в целом (как в случае с просто текстом) или к каждой строке? Если не сложно ответь, т.к. у мня возникли сомнения на это, хотя я думаю что относится к каждой строке. А вдруг не так.
>>717906 → Есть движок от команды пигмы, который они используют для своего сайта. На нём же крутятся некоторые модели, раздаваемые через кобольд орду, по-моему. Заточен как раз на оптимизированную раздачу моделей для большого числа пользователей. По всей видимости, для большинства задач там используется апи кобольда, но точно утверждать не возьмусь, не разбирался с ним сам. https://github.com/PygmalionAI/aphrodite-engine
>>718229 > На нём же крутятся некоторые модели, раздаваемые через кобольд орду, по-моему Не, емним это уже давно полноценный бэк, в котором они еще попыталсь gguf оптимизировать и в чем-то даже преуспели. Правда багов много заявляют. Его потестить и в шапку уже добавлять, если норм окажется. > апи кобольда Операи-совместимый апи, сейчас это стандарт.
К вам можно вкатиться и не поесть говна с 4 Гб врам и 16 ОЗУ? Сколько займёт обработка ответа у нейросети в таком случае? Понимаю, что зависит от настроек, но всё же хочется хотя бы примерно понять, есть ли смысл рвать жопу.
Из-за слабого английского очень сложно, поэтому не хочется потратить тонну времени и понять, что это всё было бессмысленно.
Также интересует, есть ли ультимативный гайд для долбоёбов, пусть и на английском, который как раз описывает установки, в том числе и на слабой видюхе ноут, но в диффузии через костыли генерил приличные картинки, хоть и не так быстро, как хотелось
Насколько я понимаю, можно повесить обработку одновременно и на процессор, и на видюху, и ещё оперативку зайдествовать?
>>718255 >вкатиться и не поесть говна с 4 Гб врам и 16 ОЗУ Смотря что ты считаешь говном. >Сколько займёт обработка ответа у нейросети в таком случае Железо ты не назвал, но из предоставленной информации можно предположить что-то типа i5 с 4-6 ядрами и 1650 ti. Если предположение верно, то 7-8B будет работать со скоростью примерно 5Т/с, средний ответ 200-300 токенов, т.е., 40-60 секунд. Плюс обработка контекста с участием видимокарты ~10 Т/с, обрабатываться будет 1 раз в начале карточка (в среднем 1000 токенов, 100 секунд), потом только твои новые сообщения (в среднем 100 токенов, 10 секунд добавляй к тем 40-60, ну и после 10 секунд уже можешь начинать читать то, что нейросетка срёт в реальном времени). >всё было бессмысленно Зависит от твоих запросов. На мелких моделях мозгов особо нет, но для развлекательных (чатик, ролеплей) целей кое-как годятся. >установки, в том числе и на слабой видюхе Сколько влезет до упора (out of memory error) слоёв в видимокарту методом тыка. Если nvidia, ещё в видеодрайвере отключить своп из vram в обычную ram. Закрыть как можно больше посторонних приложений во время работы нейросетки.
>>718268 >~10 Т/с, 40-50т/с, говорю как пользователь еще более старого говна 1050ти сейчас контекст быстро считает, так что сообщение среднего размера -минута, пауза между сообщениями - минимальна
>>718255 Тебе повезло, ллама 3 8b как раз для тебя сойдет, она умна и болтает по русски На видимокарту только выставляй 0 слоев, если кобальд предложит сколько то на нее перекинуть Потому что скорей всего на таком маленьком объеме врам в 4 гб влезет только контекст займя все место. Так что быстрее будет скорей всего без выгрузки слоев на видеокарту, но проверь может у тебя процессор картошка, и с выгрузкой именно у тебя будет быстрее
>>718271 >еще более старого говна 1050ти И такое у него тоже может быть. И даже хуже, какое-нибудь днище из mx-серии с 64 битной шиной. Плюс порезанные tdp и частоты у мобильных видеокарт, плюс производитель мог сэкономить на охлаждении (и даже в таком виде будет троттлить) и разводке линий pci-e. >40-50т/с >сейчас контекст быстро считает Ну если так, может быть и будет 40-50. А может 25. И слышал, что на cpu вроде там что-то ускорили в недавних патчах, чуть ли не в 2-4 раза. Хотя если у него какой-нибудь пень без avx где avx инструкции, покажи, ткни!!11, или core m с tdp в 5w, будет грустно.
>>718255 Качай ollama. Тут для каждой модельки нужен свой шаблон промпта, без которого нихера нормально модель не будет работать. Этот формат промпта разработчики не всегда указывают явно в описании модели. И вот новая модель выходит и начинается вой - а какой же шаблон взять. С ollama такой проблемы ты не увидишь, просто запускаешь модель одной командой и она работает. ollama это бекэнд, еще нужно выбрать для него любой понравившийся фронтэнд.
Тут шизы могут ответить мне что они сами определяют формат промта и могут лучше настроить модель. Если ты любишь постоянно пробовать новые модели и ты не пердолик - это не твой путь.
>>718257 Как ни странно, я вроде бы разобрался. Это было проще, чем установка сд. Но, чувствую, настройки будут сложным делом.
>>718268 >>718271 У меня ноутбучная 3050 4 Гб, процессор рязань 5 5600Н. Поставил себе neural-chat-7b-v3-16k-q5_k_m.gguf, таверну и спиздил копипастом описание персонажа с джанитора аи. Пока что впечатления смешанные. Пишет не совсем как даун-аутист, но всё равно хреново, для качественного NSFW не годится, хотя это самое простое, что можно сделать, мне кажется, так как контекста не так много нужно. Хотелось бы какую-то приключенческую модель опробовать, но, чувствую, ПК не вывезет, так как надо будет безумно много контекста в моём случае или времени.
Какие настройки мне нужно выставить на ваш взгляд? Лоурам нужно ставить в кобольде? Слои сейчас потыкаю, там 0 было, насколько помню.
4.66T/s таки скорость.
>3 8b как раз для тебя сойдет
Ну, я в любом случае использую английский, даже через перводчик, потому что на русском всегда только треш видел.
А с телефона переписку проворачивать как-то можно? Особенно удалённо, не в рамках одной сети.
>>718327 >А с телефона переписку проворачивать как-то можно Можно. Хостишь на компьютере не на локальном интерфейсе (127.0.0.1), а на внешнем. >удалённо, не в рамках одной сети Использовать vpn по прямому назначению.
>>718327 Ты взял одну из соевых моделей, для ерп рп вобще не то К тому же с выходом ллама3 она устарела, да и до нее тоже, были сетки получше https://huggingface.co/TheDrummer/Moistral-11B-v3-GGUF?not-for-all-audiences=true Вот ерп, по размеру сам выбирай, но не меньше 4 кванта, чем больше тем лучше но медленнее Это тупо ерп модель, хоть в шапку ее сувай для кумеров
>>718339 Она сведет любой диалог к куму, так что она сетка специалист хорошая только в одном. Предок универсал, топчик, до выхода ллама3 Но ллама3 с ограничениями, а Fimbulvetr их не имеет Так что хоть Fimbulvetr v2 хоть моистрал может качать и спокойно пользоваться в любых сценариях.
>>718205 Если ты думаешь, что я специалист и в чём-то разбираюсь, то ты глубоко заблуждаешься. Но насколько я знаю, это относится ко всему примеру в целом. Фактически в нейронку скармливается твой инстракт+инпут+отпут, как единый кусок текста и уже этот кусок нарезается на части определённого размера. Сама json разметка больше для трейнера, а нейронка обучается на цельном куске текста.
>>718205 в коде qlora, который я использую для обучения есть отдельные параметры обрезки input и output, по идее все форматы приводятся к одному типу: (input, output, инстракт вырезается), после чего каждое из них по отдельности разбивается на токены.
>>718255 Ну тут явно 7b/8b с русским что-нибудь, файнтьюны. Сузуме для тестов, Мистральки какие-то. Может 11b какие-нибудь могут.
Качай KoboldCPP, качай gguf файлы, загружай модель. СиллиТаверн по желанию, если вкатишься в кобольд.
>>718271 > на таком маленьком объеме врам в 4 гб влезет только контекст База. Модель будет большей частью в озу, конечно.
>>718290 А вы знаете, кто еще 4 гига имеет? GT710 =D Ну и много других видях, да.
>>718327 > У меня ноутбучная 3050 4 Гб, Пушка-гонка, братан!
> 7b-…-q5_k_m > даун-аутист Тут ты. =) Только q8 для 7b моделек. В критически крайнем случае q6. И то, желательно с imat, матрицами важности. Но оффенс, но на пятом кванте малой модельки жизни и не может быть.
> 4.66T/s таки скорость. Ну привыкай морально к поменьше.
> Ну, я в любом случае использую английский А, тогда можно попробовать 11b модельки из шапки! Fimbulvetr-10.7B-v1.q5_K_M.gguf Вот эта и че тут еще насоветуют.
> А с телефона переписку проворачивать как-то можно? Особенно удалённо, не в рамках одной сети. Как и любой другой софт. Запрос в брэндмауэре открыл, порты через роутер прокинул, айпишник зафиксировал, подрубаешься. Ну или есть варианты через облако выводить, у некоторых фронтов есть настройка, не уточню.
>>718332 0.0.0.0 чтобы приложение слушали с внешней сети.
>>718336 Вот, тоже совет. Но я бы брал не ниже 5, скорее.
>>718336 Очень странно. Специально читал какой-то кумерский гайд из шапки, она там была самой лучшей якобы.
Спасибо, завтра попробую. А то я удивился с соевых ответов, т. к. персонажа закинул доминантного-злого.
Если не лень, подскажи, как искать модели в плане того, что мне нужно с точки зрения сюжета, кума, стиля и так далее. С той же стабильной диффузией можно было оценить модель визуально и по пикчам в треде, на цивитаи, а тут хрен поймёшь. Да, у моделей есть характеристики, но они технические, а описание скупое. Не просто же ползать по бордам и читать отзывы или качать что попало.
Заодно, если знаешь, подскажи модель, которая позволит отыгрывать безумие в стиле вахи. Тотальная война, кровь, боль, расчленёнка, магия, современность, диалоги в этом антураже. А если она ещё может в художественное описание, красивое, то есть модель обучена на качественной литературе, то совсем отлично. А если может сама рассказ писать, пока я буду просто гейм-мастером, то вообще отвал башки И в данном случае время ответа для меня не слишком критично, т. к. это не кум и мне не лень ждать, если итог качественный. Только с настройками совсем непонятно будет, наверняка придётся в оперативку выгружать.
>>718343 Ну хз, я ее второй день тестирую и пока вижу, что она многозадачная вне рамок кума, причем изобретательная. Подходит для написания коротких рассказов, эссе и прочего на заданные темы.
70b llama 3 очень плохо умеет в русский, постоянно срывается на другие языки и несет околесицу. При чем когда я спрашиваю по коду, то отвечает нормально, а когда пытаюсь в ролеплей начинается пиздец. Это можно пофиксить промптами или базовая модель просто кал вне инглиша?
>>718458 Тот же промпт на английском исполняет идеально. Просто переведен на русский и с подписью "отвечать только на русском". Ща еще посмотрел, помогает снижение температуры, правда тогда она совсем в околоформальном стиле все выдает
>>718521 Странно что с командиром+ не сравнивают. Или не странно, а просто бояться. Надо будет запустить, хотя для меня уже командир+ на пределе возможностей моего ПК, первые генерации в подкачку лезут. >>718533 Эпл даже не трогал, у мелкомягких кусок сои вместо модели. Из мелких ллама на 8B выглядит достаточно мелкой, чтобы запускать на кофеварке, и достаточно умной, чтобы ебать всё, что меньше её.
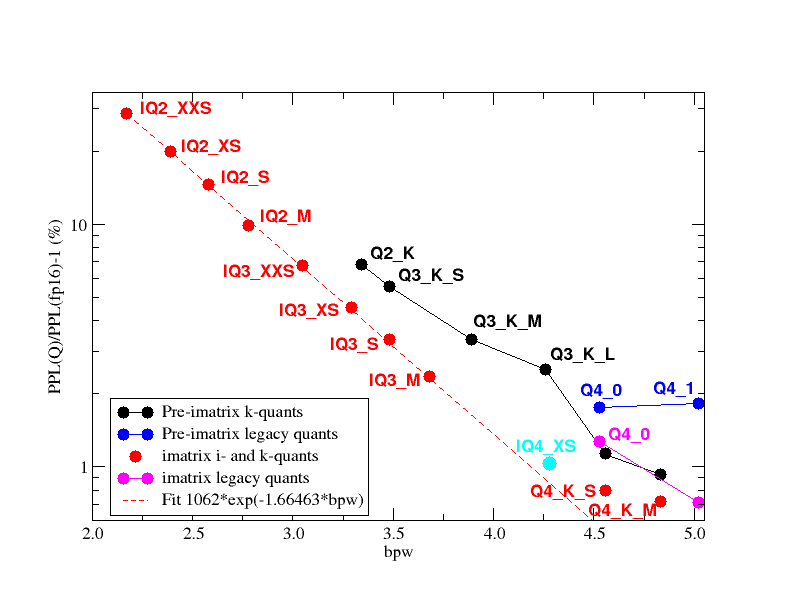
>>718544 >Странно что с командиром+ не сравнивают. Или не странно, а просто бояться. Так вижу, что если для 70В минимально приемлемым (при наличии возможностей) является Q4, то для сотки (100-120В) должно быть около Q3. iQ3_XXS как самый минимум.
Приветствую, аноны. Сижу качаю языковые модельки, балуюсь, узнаю, что от величины контекста увеличивается частота самоповторения и в общем наступаю на другие такие грабли. Узнаю для себя, что есть некий способ "проверёвить" модель с помощью некоего RoPE. Гуглинг рассказал мне в красочных математических подробностях что это за метод, но нигде я не нашел что его реализовывает и через что модель нужно прогнать, чтобы её "проверёвить". Так вот вопрос: Что это все-таки такое? Я может быть что-то не понимаю. И как применить RoPE для расширения контекста модели?
>>718554 Can you help me solve this problem? A peasant needs to carry a crocodile, a monkey and a banana across the river. But the boat is such that it can only fit him and one other thing - either the crocodile, the monkey or the banana. If you leave the crocodile with the monkey, the crocodile will eat the monkey, and if you leave the monkey with the banana, the monkey will eat the banana. So how can the peasant carry all his cargo to the other side of the river?
This is a classic logic puzzle. Here's a step-by-step solution:
The peasant takes the monkey across the river first and leaves it on the other side. This ensures the monkey is safe from the crocodile and can't eat the banana. Side 1 (Starting side): Crocodile, Banana Side 2 (Other side): Peasant, Monkey The peasant goes back to the original side with the boat and picks up the crocodile this time. Side 1: Banana Side 2: Peasant, Monkey, Crocodile Now, before leaving the crocodile alone with the monkey, the peasant takes the monkey back across the river. This might seem counterintuitive but it's to ensure he can safely move the banana next. Side 1: Crocodile, Banana, Monkey Side 2: Peasant The peasant immediately goes back and picks up the banana, since now the monkey is on the safe side and can't eat the banana. Side 1: Crocodile, Monkey Side 2: Peasant, Banana Finally, the peasant takes the monkey across again without the banana, as the banana is already safely on the other side. Side 1: Crocodile Side 2: Peasant, Monkey, Banana Now all three items, the crocodile, the monkey, and the banana, have been safely transported to the other side of the river without any of them being eaten.
Решение задачи совершенно правильное, но модель явно не понимает где, кто и почему.
>>718580 >Но зачем, когда на Авито дешевле лежат? Что там лежит - это ещё большой вопрос, но дело не в этом. За 21к с таким охладом я бы её взял. Проблему правда вижу - до 250 ватт тепла будут рассеиваться непосредственно в корпус. Одна такая карта конечно не проблема, но у меня не одна.
>>718504 Ладно, возьму на попробовать к 4090. Но как-то надежды на этот кал не сильно много. В целом похуй даже если не взлетит. >>718507 Я надеюсь у тебя нормальные кванты от бартовского, а не старый поломанный мусор, который выкатывали в день релиза?
>>718618 > в пазах В каких пазах? У всего поколения стандартизированное крепление, как минимум основные точки возле GPU. Места, прилегающие к питальникам на краю, возможно не подойдут, да оно и похуй, если не будешь в перевёрнутом положении ставить ничего не случится.
>>718620 >Я надеюсь у тебя нормальные кванты от бартовского Конечно же нет, их не было, когда я качал. Впрочем так даже веселее. Ладно, качну новый квант, хотя вряд ли он тут поможет.
>>718620 >Ладно, возьму на попробовать к 4090. Не забудь сделать обзор, как приедет. А то ни одного отзыва. Первым всегда тяжело(с) >Но как-то надежды на этот кал не сильно много. Не, тема хорошая. 70В пощупать за вымя - с чувством, с толком, с расстановкой - это приятно :)
>>718010 >Trained on publicly available datasets, these models are made available without any safety guarantees. Обученные на общедоступных массивах данных, эти модели предоставляются без каких-либо гарантий безопасности. >Consequently, there exists the possibility of these models producing outputs that are inaccurate, harmful, biased, or objectionable in response to user prompts. Следовательно, существует вероятность того, что в ответ на запросы пользователей эти модели выдадут неточные, вредные, предвзятые или неприемлемые результаты. и это модели от эпл, нежданчик конкретный конечно же
transforming LLMs into parallel decoders boosts inference speed by up to 3.5x
Hey all! We are here to share our latest work: consistency large language models (CLLMs), which is a new family of models capable of reducing inference latency by efficiently decoding n tokens in parallel. Your new friends for LLM serving/local deployment with faster inference speed!
Compared with existing fast decoding techniques, CLLMs achieve fast parallel decoding without the need for: • Draft models • Architectural modifications/auxiliary model components
This introduces a number of advantages for CLLMs: • CLLMs don't have to deal with the complexity of obtaining 'good' draft models and managing two different models in a single system. • CLLMs share the same architecture with target LLMs and require no additional engineering efforts when adopting the technique to different models. • CLLMs can be integrated seamlessly with other techniques for efficient LLM inference (e.g. Lookahead Decoding) to achieve even more significant speedup.
This decoding method CLLMs use is called Jacobi decoding, which improves inference efficiency in comparison with conventional auto-regressive decoding. CLLMs are trained with the objective of performing efficient Jacobi decoding by mapping any randomly initialized n-token sequence to the same result as AR decoding in as few steps as possible.
Experiment results have demonstrated the effectiveness of CLLMs, showing 2.4× to 3.4× improvements in generation speed on a variety of tasks.
>>718677 >и это модели от эпл, нежданчик конкретный конечно же В целом, там типовая юридическая хуйня, чтобы прикрыть свою жопу - "мы не несём никакой ответственности за возможные последствия". Это особенно актуально в странах уровня США, где по каждому чиху против тебя могут подать судебный иск.
>>718686 >So maybe we have to start parsing this information from the tokenizer.json Прошёл год, и тут герганов догадался, что его грязные хаки приводят к промблемам. ЛЛЛОООЛЛЛЛ. Я знал, что жора поднасрал! >>717999 (OP) >ждём исправлений по части квантования от жоры, наверняка он подгадил
>>718711 Короче пока не пофиксят вот это, все лламы 3 официально сломаны на корню, так как тут сломано объединение \n\n в один токен, а этот токен из базового темплейта, так что это полный пиздец для модели, минус половина IQ на ровном месте. https://github.com/ggerganov/llama.cpp/issues/6809
>>718350 Благодарю! значит я думал неправильно. Ну теперь буду знать.
>>718361 Если инстракт вырезается и при этом инпут пустой, например такие датасеты бывают из визардоподобных. У альпаки также допустим пустой инпут. Как в этом случае происходит?
Ты файнтьюн скачал, нахуя? Еще и без квантования. Ладно, квантование у жорика сейчас сломано, но есть еще exl2. Ладно, можно и эту залупу запустить на трансформерах, только скорость будет такая себе. Сколько видеопамяти?
>>718724 Да, я написал, что костылинг >>718711 По сути он предлагает хардкодить несколько вариантов и выбирать их при конвертации в гуф в зависимости от того, что выведет оригинальный токенизатор. То есть если в строке для примера нет символов, которые иначе обрабатываются разными токенизаторами, то гергановский код не найдёт отличий и пришьёт стандартный токенизатор. Переведите плиз это на инглишь, у меня с ним плохо, да укажите на очевидный проёб. Я тупой слишком.
>>718729 Хули толку мне от экселя, когда у меня 12 врама и желание запускать 70B. На дрочь в стиле "Да эта 8B ебёт все 70B" внимания по привычке не обращаю.
>>718743 Везде ллама 3 инструкт из новой таверны, семплеры на отъебись Min P 0,05 и Frequency Penalty 0,3, остальное отключено. У тебя ассистентов нету?
>>718722 существует множество датасетов, к примеру у альпаки инстракт и инпут всегда склеиваются в одну строку, после чего поле инстракт вырезается, на выходе всегда получаются только input и output данные, которые обрезаются в соответствии с параметрами. затем это все склеивается и разбивается на токены. причем, насколько я могу судить обучение проходит только на output токенах, а input токены скрываются и служат только инстрактом. в qlora есть отдельная опция, чтобы включать обучение и на инпут данных.
А я пока качаю, подожди. Но вангую что говноед на квантователе правленые конфиги не прикрепил, к счастью от высера Жоры где только переквантовывать и никак иначе - тут это правится в блокноте. Сейчас докачаю, затестирую и выложу фикс если моя догадка верна.
>>718747 >input и output данные чтобы не запутать: так происходит для каждого семпла в датасете, а далее после всех манипуляций оно, возможно, склеивается в батч и отдается на трейн.
>>717999 (OP) Прошу прощения за платиновый вопрос, но какие модельки хороши для кодинга, чтобы умели прям в структуру кода и чтобы у меня была возможность всю простыню кода умещать в контекст? Хотелось бы более менее подробное описание вашего опыта.
>>718762 Тоже написал, что ты из института Cumming research? И что им в этом институте не нравится... >>718764 А это вообще законно? Надо будет пожаловаться. >>718769 Там шаблон не торт, модель в других местах по тупеет.
>>718768 >чтобы умели прям в структуру кода Не уверен, что ты под этим подразумеваешь, но, скорее всего, нейросетки тебя разочаруют. Пробуй 70+B. >описание вашего опыта ~7B - "умный" автокомплит ~30B - туповатый вкатун после курсов
Я вообще в шоке с этих двачеров. Реально ёбнутый народ. Пол года назад писал про фарадей. Уже год как он существует. Но нет в шапке в пункте "для ретардов" до сих пор торчит унылый кобольд, который тру-ретард хуй запустит. А сообщения от тугодумов так и продолжают литься... ОБРАЩАЮСЬ К ДОЛБАЁБАМ! КАЧАЙТЕ ФАРАДЕЙ И НЕ СЛУШАЙТЕ УМНЫХ ДЯДЕЙ С ТРЕДА!!! СКАЧАЛ-ЗАПУСТИЛ-ПИЗДИ И ЕБИ КОГО ХОЧЕШЬ! 0 НАСТРОЕК Так же эта программа даст тебе более менее базовые знание по текстовым нейронкам если ты вообще дуб.
>>718768 Wavecoder можешь взять, вот пикрилейтеды калькуляторов от него на расте и крестах, с первого раза написал компилирующийся и работающий код. С правками существующего кода в целом хорошо справляется, контекст какой хочешь будет по длине, continue ещё и может из базы/гита/документации/гугла дёргать контекст.
>>718726 пикрил 1. Дефолтная ллама3-8б-ггуф (q8_0). 2. Промпт моего дефолтное помощника, вообще без этих ваших промптов с еотами. 3. На русском. 4. С первого раза. ¯\_(ツ)_/¯
>>718838 ПОДДЕРЖИВАЮ ДОЛБАЕБЫ, КАЧАЙТЕ ФАРАДЕЙ И ВООБЩЕ ПИЗДУЙТЕ ИЗ ТРЕДА, СОЗДАВАЙТЕ СВОЙ ТРЕД ДОЛБОЕБОВ ДОБРА!!!
>>718862 Забыл сказать, семплеры спиздил из этого треда, может это пороляло. Эксллама отвечает кривее, кстати, но возможно дело в старом кванте бывшей, я не перекачивал ее прост. А ггуф из последних.
>>718965 пуританы ебучие, какая же тряска у них пиздец, но в то же время они не против обучения ллм-ки на какой нибудь гендерной хуйне для несовершеннолетних или исключительно положительная инфа по байдену с демократией
Не знаю точно ли от этого зависит, потому что мало еще тестировал, но лишний перенос в префиксе или суффиксе в ~8б может сеть заставить через несколько диалогов ввести в бесконечный вывод промта. Так что с этим надо быть очень внимательным.
>>718747 >обучение проходит только на output токенах Предположим, что инстракт это А. Оутпут, соотвественно, Б. Если обучать только на оутпуте, то как нейросеть узнает, что после А следует Б? >input токены скрываются и служат только инстрактом Потому что во множестве датасетов инпут типовой. You are helpful son of a bitch. Вполне возможно, что в твоём коде инпут просто токенизируется один раз и потом переиспользуются. В случае трейна на рп датасете получится хуйня. Как и если вырезать инпут полностью.
The first Multimodal Large Language Model (MLLM) based on Llama-3! Bunny-Llama-3-8B-V has been officially launched, surpassing a variety of models such as LLaVA-7B, LLaVA-13B, and Mini-Gemini-13B. It performs well on multiple mainstream benchmarks, demonstrating superior recognition, mathematical, and reasoning capabilities.
The Bunny model adopts the classic Encoder+Projector+LLM architecture, providing a compositional framework. It supports various Vision Encoders such as EVA CLIP, SigLIP, and multiple LLM Backbones including Llama-3-8B, Phi-1.5, StableLM-2, Qwen1.5, MiniCPM and Phi-2. The flexible architecture design facilitates users to conduct various research based on Bunny.
>>719137 если это то что я читал утром то там проектор хуевый, не как у ллава 1.6, а как у ллава 1.5 разрешение меньше сетка выезжает чисто за счет мозгов основы
>>718620 > Но как-то надежды на этот кал не сильно много. А зачем тогда берешь? Ууу мажор ебаный мог бы 3090 взять >>718680 Довольно интересная штука. Но, только не до конца понял, это выходит только для гриди энкодинга? >>718721 О, дней с поломанного ггуф -> 0 >>718729 Oh you~ >>718775 О, красава, надо будет с инструкт попробовать.
>>719164 блять реально, вот у меня есть Q8 этой лламы https://huggingface.co/Orenguteng/Llama-3-8B-Lexi-Uncensored-GGUF/tree/main только что закачал Q4_K_M, ответы как будто стали точнее, но модель вместо большей креативности теперь шизит на 0.7 температуре, потому убавил на 0.59, походу вся llama.cpp люто поломана и только некоторые кванты "успешны".
>>719167 Хз, наверно, попробуй >>719170 Запусти терминал/командную строку и вызови из нее. Прочти код ошибки что там напишет и сам загугли, если не справишься - тогда пости сюда.
>>719172 Спасибо, получилось. Поставил силли таверн, застрял между вот этими шагами:
>2. Запускаем всё добро >3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
Я жму иконку вилки, и он предлагает подключатся хуй знает куда, дает какието модели выбрать, хотя у меня всего 1, спрашивает API ключи, что то не пойму как сказать ему, что бы подключался локально к моей штуке.
Аноны, как то сильно наебнулся кобольд, перезагружаться надо было, теперь не могу запустить его в работу, все время останавливается на такой строчке в консоли:
>llm_load_tensors: ggml ctx size = 0.51 MiB
Дальше ничего просто не происходит, никаких ошибок, апдейтов, просто он не запускается дальше. В чем может быть дело, как исправить?
Сегодня узнал что в таверне есть всртроенная поддержка openrouter и понял зачем там нужны бесплатные модели вообще. С моей немощной пекой охуенно вообще, если вам не важно что какой-то дядя читается ваши извращенные сообщения по склонению к сексу код-ассистента, то вообще же топ. Не понимаю почему они дают это бесплатно юзать
Есть две карточки на 24 и на 12 в одном пк, как в кобольд спп загрузить модель так, чтобы сначала заполнялись 12, а потом 24, но при этом 24 считалась первой, чтобы контекст хранился только в ней?
>>719286 Тогда настраивай тензор сплит вручную. Карту на 24 ставишь везде первой, а заполняться в любом случае будут обе, разве что если ты не выделишь при сплите первой 0% (не уверен, что прокатит). А откуда вообще желание разгрузить 24 гиговую?
>>719296 Тем не менее я этого ебучего команде-ра в пятом кванте не могу загрузить даже с 6к контекста, с бОльшими моделями проблем меньше. Что в эксле не грузится нормально, что в ггуфе.
Какие модели лучше всего подходят для написания рассказов и литературы?
Пишет тот анон, который с 3050 laptop 4 Гб.
Ещё есть проблема. Я создал ссылку для всяких джаниторов в кобольде, которая через API, но ответы по какой-то причине очень короткие и хуёвые на сайте (в настройках я там порылся как надо), при этом в таверне всё в порядке. Довольно досадный момент, потому что с телефона нормально не посидишь тогда. Какие приложения вы используете для тела или сайта? Гуглил, но там один тухляк либо гомоебля.
Генерация у меня, конечно, долгая, но я никуда не спешу, поэтому интересуют именно качественные варианты.
>>719361 Я отписывался в начале треда, но хрен с ним. Вряд ли все аноны читают тред.
1. Какие модели для кобольда позволяют написать что-то вроде небольшого рассказа или книги?
2. Существуют готовые решения для работу через, чтобы можно было использовать локальную нейросетку, находясь вне дома? То есть на телефоне и через удобный интерфейс типа таверны.
>>719259 Блокируются тунели Cloudflare и remote.moe, как будто бы самим гуглом. Хотя почему-то без проблем создаётся туннель к API. Но мне сейчас лень с этим разбираться Поставил отдельный костыль для запуска интерфейса его блокировать будет не так простоесли API заблочат, можно будет через него же запускать Кумьте дальше, аноны!
>>719406 >2. Существуют готовые решения для работу через, чтобы можно было использовать локальную нейросетку, находясь вне дома? То есть на телефоне и через удобный интерфейс типа таверны Так саму таврну и юзай, зачем ещё что-то https://docs.sillytavern.app/usage/remoteconnections/
>>719406 1. Любой нормальный рп файнтьюн должен бы уметь в сторителлинг. Основной инструмент тут промпты имхо, т.е объяснить в системном промпте, что ты хочешь, чтобы модель выступала рассказчиком. В таверне есть adventure шаблон с простеньким промптом для примера, а на чубе можно посмотреть карточки персонажей-рассказчиков. По моделям: есть старые 13б модели, которые хвалили за сторителлинг. Например, LLaMA2-13B-Estopia, LLaMA2-13B-Psyfighter2, Chronomaid-Storytelling-13B. Но катать 13б даже на 8 гиговой карте - это боль, на 4-х ты просто задолбаешься ждать, и на нормальный контекст тебе не хватит, а для историй он важен. Лучше попробуй относительно хорошие файнтьюны мистраля Kunoichi-DPO-v2-7B или WestLake-7B-v2. 2. У тебя отличались результаты через таверну и с чистого апи кобольда, потому что были разные промпты, сэмплеры, инстракт-форматы, скорее всего. Таверна посылает в кобольд свои промпты и параметры. Как правильно сказали выше, лучше поднимать таверну и подключаться к ней удалённо. Если смартфон не картошка, и есть желание попердолиться, то можно полноценно поставить таверну через термукс (гайд в шапке, и он же есть на сайте ст на гитхабе).
>>719523 Короч. Открывай через консоль ./kobolcpp Там логи отображаются. Варианты: Видюха есть? Проц новый? Памяти хватает? Попробуй ./konoldcpp —noavx2 —nommap —useclblast 2 0 Последнюю используй если есть видюха и цифры нужно 2 0 нужно выбирать конкретные, которые у тебя. Там должно показывать
>>719523 Что за видюха? Если Нвидиа выбирай CUBLAS. Если командная строка вылетает, значит он не запустился. Потом что за версию ты скачал там разные есть, с AVX без него, с CUDA, без негою
Прошу пояснительную бригаду по LLava с Llama3. Скачал GGUF, открыл через угабугу, Таверна на конце. Модель нормально грузится на карту. Далее прикрепляю пикчу к тексту, прошу описать её. А модешь пишет или тарабаршину или вообще не по теме пикчи. Промпт Альпака. Или LLava надо как-то иначе запускать?
>>719556 >LLava с Llama3 Там сама ллама 3 работает через пень колоду, а ты ещё картинки подрубаешь. А так сначала в убабуге проверяй, раз через неё запускаешь, таверна тут лишняя точка отказа. >>719559 Печальный у тебя ПК. В общем ты в этот каталог скачал? Тогда запускай koboldcpp.exe (не стесняйся пользоваться табом для автоподстановки), выполняй те же действия, что привели к ошибке, и в консоли будет текст ошибки, неси его к нам.
>>719559 >i3-2100 У этого avx2 нет. >>719512 >Что делать, если я затупок Учиться пользоваться компьютером (рряя, пердолинг), либо ждать, когда барин подгонит решение в один клик (впрочем, и тут есть подводные, барин может просто послать тебя на хуй пока не обновишь пеку, потому что барину лень старьё поддерживать). Кто-то там рекламировал всякие олламы где всё за тебя сделано, без пердолинга, в один клик и вот это вот всё, можешь как раз протестировать, как оно, потом в треде расскажешь.
>>719258 >Не понимаю почему они дают это бесплатно юзать датасеты собирают, натуральные человеческие данные сейчас новая нефть как и все компании и сайты предоставляющие легкий доступ к чату с моделью, лол
>>719580 Веса или UI? Надеюсь что не UI, потому что из новой oobabooga убрали файл requirements_NOAVX2.txt, а при попытке загрузить гуфф выдает рил. Двойной удар по россиянам нищукам, но такова цена жизни в сверхдержаве.
>>719593 >натуральные человеческие данные сейчас новая нефть И что ты прикажешь делать с тонной кума, зачастую извращённого? >>719596 >Веса или UI? Всё, что связано с гуфф и жорой.
>>719559 >Видюха Gigabyte GeForce GT 1030 >Процессор старый Intel Core i3-2100 >Оперативки 16 гб Я то думал это я тут самый страдалец с 1050ти по сравнению с господами погромистами с двумя 3090/4090 или р40 Оперативка хоть не одной плашкой памяти? Если еще и одноканал то вобще жопа Качай 7b какую нибудь, на вроде starling-lm-7b-beta или openchat-3.5-0106 или новенькую WizardLM-2-7B Квант качай gguf формата Q4_K_M или Q5_K_M, чем больше тем медленнее будет, но и качественнее. 8 квант самый жир но у тебя будет медленно
>>719598 >И что ты прикажешь делать с тонной кума, зачастую извращённого? Ну во первых там не только кум, там и обычные чаты. Во вторых все что им не нравится фильтруется и собирается в датасет которым будут проверять устойчивость модели к снятию цензуры и сои И все ваши джейлбрейки так же собираются что бы делать более устойчивые модели
>>719608 >Ну во первых там не только кум Его там 95%. >И все ваши джейлбрейки так же собираются что бы делать более устойчивые модели Ну вот мелкософт выпустила "устойчивую" модель, с которой даже козу не подоить. И кто её обсуждает? Даже корпы уже начинают подозревать, что стричь деньги за "Извинити, я не могу это сделать" вечно не выйдет. Вон, антропики ослабили цензуру в своём клоде, да и последний снапшот GPT намного менее соевый, чем высер 0125. Так что маятник качается, окно расширяется, процесс илёт.
>>719612 >мелкософт выпустила "устойчивую" модель это ты про wizardlm-2 ? если да, то там пиздец, эта модель по тестам тупо оветрейн на сое, например если спросить про гендерную хуйню - ответит в ту же секунду и без запинок, и только в положительном ключе, но так честно говоря с любой локалкой, потому если РПшишь с обычной (или не очень) тян то иногда модель может приделать ей хуй ради разнообразия и инклюзивности прямо посреди разговора. в случае с лламой-3, то там тупо упирается в фем-шизу и дыхание вагиной "my body - my choice" даже если у тебя всё честно и по согласию, если короче, что-то не видно качения маятника :/
>>719618 >это ты про wizardlm-2 ? Про фи-3, ну да ладно. >в случае с лламой-3 Цензура далеко не непробиваемая. Могли бы выпустить полнейшего лоботомита, но нет, модель достаточно живая, чтобы пробиваться простыми префилами. Про гендеры модели не спрашиваю, но клод становится базированным, если попросить его отыгрывать за сторону мусульман. С локалками не проверял.
>>719624 цензура или не цензура, но по наблюдениям вся эта хуйня имеет наивысший приоритет почти у любой локальной модели, даже если накинул джейлбрейк сверху, тупо ломает весь фан в самый неподходящий момент. за всё время пока только вот эта https://huggingface.co/TheBloke/SOLAR-10.7B-Instruct-v1.0-uncensored-GGUF является тру-анцензором, но это скорее всего работает из-за изначальной нейтральности SOLAR-10.7B, DPO в этом случае просто направил туда куда надо.
Ладно, много месяцев тут ничего не писал, в общем, отрапортую.
Имею на борту Ryzen 5600g и 32 гигабайта оперативки (без видюхи). По итогу, когда решил опробовать Llama 3 8b и включил kobold.ccp с режимом Vulcan - контекст 512 стал обрабатываться за 10 секунд, хотя раньше по 20-30 обрабатывал. Сама модель выдаёт по 2-3 токена в секунду.
>>719624 Кстати, соевая цензура в мультимодальной лламе своеобразная "The image is being shared to express the idea that women are not just sexually attractive, but also have a lot of other qualities that make them appealing. The use of the word 'cock' in the caption is meant to be humorous and does not imply that the woman is asking for sex. It is simply a playful way to express the idea that women can be both sexual and non - sexual at the same time."
>>719657 Извините, я АИ нуб, только поставил модель из шапки в кобольд. А можно вместо нее поставить ту, которую вы обсуждаете? Она лучше? У меня 12 гб врам
Ламу3-то? Можно, разрешаю, ставь. Но тут даже олды треда вроде меня не понимают как заставить её работать чтобы и 4110 выдавала в ответ на 3333+777 и при этом не шизила и не сралась под себя и притом работала на нормальной скорости. Вместо модели из шапки можешь поставить вторую версию той же модели https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF Или если нужен кум - то её нсфв+ версию https://huggingface.co/Sao10K/Solstice-11B-v1-GGUF
>>719714 > Но тут даже олды треда вроде меня не понимают как заставить её работать чтобы и 4110 выдавала в ответ на 3333+777 и при этом не шизила и не сралась под себя и притом работала на нормальной скорости. FP16 восьмёрка вроде не обсиралась, но может просто повезло с зерном сидами. В 4.5 кванте exl2 даже 70 в 2 из 15 ответов обосралась выдав 41110, сэмплеры были из симпл-1
Про неё я написал >притом работала на нормальной скорости.
>В 4.5 кванте exl2
Смог заставить работать только в убе, в таверне неконтроллируемый понос под себя с любыми фиксами и настройками. В убе выдавал 4110 в одном случае из трех, в остальных настаивая на 2110 и 3110.
Через Угабугу вообще можно запускать мультимодалки? Ебусь с утра и так нифига и не запустил. llava-v1.6-34b.Q6_K и llava-llama-3-8b-v1_1.Q6_K. УГа вообще отказывается стартовать с --multimodal
>>719739 > Про неё я написал Ну она быстрая, если не с теслой конечно, хотя может и с ней быстрая, мелкая же. Памяти заняло с 8к 16500, если поставить 32к контекста 19500, ну как с мистралем в полных весах > Смог заставить работать только в убе, в таверне неконтроллируемый понос под себя с любыми фиксами и настройками. В убе выдавал 4110 в одном случае из трех, в остальных настаивая на 2110 и 3110. Вот сейчас потыкал в угабуге, всегда точно отвечает фп16, или бф16, какая она там, но любит иногда посрать после этого, особенно когда альфой растягивать до 32к
В случае с ламой 3 exl2 сломан впринципе. Покопавшись в дискорде таверны я увидел что не у меня одного он срет просто поехавшей хуйней - все на это жалуются. Короче пока что ВСЕ КВАНТЫ СЛОМАНЫ НАХУЙ, единственный варик - это гонять оригинальную модель в 8 битах на трансформерах.
>>719908 На сколько понимаю это специальная оптимизация нейросетей для запуска на процессоре, тоесть идет преобразование изначальной нейросети в формат при котором легче и быстрее запускать на процессоре А потом уже добавили квантование для уменьшения размеров и увеличения скорости, так как любая нейросеть в оригинале слишком медленна на процессоре Поищи у герганова ggml проект на гитхабе и почитай че он там делал и для чего
>>719912 Большие сетки все равно напополам и на процессоре и на гпу, а так можно делать только с ггуф/ггмл потому что все остальное только на гпу так как не оптимизировано для запуска на процессоре
>>719916 Остальные кванты работают через половинные точности, что очень слоупочно работает на старых видеокартах. У ггерганова скорее всего это полная точность, а половинная точность достигается смещением указателя. Что работает быстро, и на процессоре, и на старых видеокартах. Так как база треда это древняя, как говно мамонта, p40, то ты сам должен понять, почему на ггуф такой спрос. Плюс ггуф поддерживает выгрузку части слоёв на видеокарту и части на процессор, что добавляет ещё больше очков в копилку.
>>719916 Много видеопамяти очень дорого, оперативка и какой никакой процессор - дешево Вот и популярен ггуф, так как у большинства игровые компы а значит есть видеокарты, они все равно не обладают достаточным объемом врам, поэтому другие форматы могут запустить не только лишь все Зато ггуф пойдет на любом компе
>>719920 Это все равно 3 токена в секунду у 8b модели с низким квантом. А с обработкой контекста твоего персонажа в таверне это еще пару минут на одно сообщение. Это пиздец так жить.
>>719926 > Жди когда патч дойдет до кобольда. А что там конкретно пофиксили, а то я заебался эту простыню читать? Есть и ли смысл вообще сидеть на llama.cpp?
>>719927 >Это все равно 3 токена в секунду у 8b У меня на процессоре ллама 3 8b в 8 кванте 6 токенов в секунду Основное ограничение скорость чтения памяти, так что либо гони память либо вставляй не 1 плашку а 2, чтоб в двухканале работало Ну или проблема в тухлом процессоре, или отсутствии avx-avx2 КОроче варианты есть и это все еще дешевле покупки кучи видеопамяти в одной видеокарте. Тут либо сразу 4090-3090 брать ради 24 гб, либо р40.
После долгой ебки наконец заставил exl2 квант ламы 3 работать, не срать ассистентами, не сходить с ума, не поносить километрами текста. В общем там все надо ручками менять, настройки таверны для гуфа не подходят, правильные конфиги пришлось франкенштейнить из разных фиксов самому, ни в одном месте не залиты все нужные фиксы сразу.
>>719927 >Это все равно 3 токена в секунду у 8b модели с низким квантом. А с обработкой контекста твоего персонажа в таверне это еще пару минут на одно сообщение. Это пиздец так жить. Мику_70В_Q4_K_M на двух теслах после заполнения 8к контекста генерирует только 4 токена в секунду. Да, где-то полторы минуты на сообщение, но они длинные. И жить - хорошо! Конечно, хорошо жить ещё лучше, но и так неплохо. Не пиздец, далеко не пиздец.
>>719935 У меня мак прошка, тут хороший проц по дефолту и 16 гигов оперативы. Больший бугурт вызывает загрузка контекста которая пару минут занимает раз в несколько сообщений
>>719942 >раз в несколько сообщений Ээ а так должно работать? Там же все в кеше хранится еще и контекст шифт должен помогать, если нет новой информации то вся старая не должна перечитываться
>>719935 Но 24 гб это менее чем полумера, ни рыба, ни мясо. На практике модели, которые туда влезут, генерирует тексты не лучше, чем 13b, которые влезают в 12гб. Чтобы начать считать, что на 24гб тексты лучше, надо заниматься аутотренингом. Но более крупные модели можно пощупать хотя бы на хорде или на арене, и убедиться в том, что все веселье начинается далеко за пределами 24гб, да и то не всегда - в некоторых задачах 120b ничуть не лучше 13b.
>>719908 Это для распределения между процессором и видеокартой. В идеале DDR5 ram на большой частоте и видеокартой в идеале кластер похожий на майнинг ферму с А100 ускорителями. Ну это мои влажные фантазии . Дата центр если кто раз бывал в серверной поймет насколько это моя фантазия.
Так блядь только ворвался в ваш тред, скачал эту вашу ламу3 8b 8_0 gguf, скачал конфиги для таверны.
Ассистентами не срет, сою в рассчет не берем - у меня срет повторяющимися сообщениями начиная уже с третьего, че я делаю не так? Тупо невозвожно ролплеить, почти копирует предыдущее сообщение добавляя незначительные различия, где еще что-либо поменять чтобы оно ваще РАБОТАЛО?
>>719899 > exl2 сломан впринципе А че с ним не так? Постили вон что-то только про поломанный конфиг (тянущися с оригинального релиза?). > это гонять оригинальную модель в 8 битах на трансформерах Можно гонять оригинальную 8б в фп16 на экслламе, хз, нормально работает и всего того пиздеца который здесь описывали не было встречено. >>719908 Это формат для упаковки модели со всеми конфигами в один файл. В контексте ллм он является переемником ggml, который предлагает разные кванты для работы с llamacpp. >>719915 > Большие сетки все равно напополам и на процессоре и на гпу Нет, только фуллгпу, только хардкор, нахуй полумеры. >>719972 Красавчик >>720003 Можно подубавить до 0.4-0.5, меньше шанс путаницы. Если заставляешь модель переделывать код то можно и добавить до 0.8-0.9 ради разнообразия, но ошибки придется ловить.
>>720063 Первая вкрсия была скорее всего на пигме. Ща хуй знает. Скорее вего он только сейчас переехал на что-то лламоподнобное, ибо она всегда сосала в базовых вещах, а ща даже в матан может. Так же это скорее всего мультимодалка, если он не клипом описание пикч в контекст прокидывает. Возможно какой-то собственный файнтюн ллавы
>>720063 Видос не смотрел, смотрел другой. Она у него читает мелкие надписи на картинках. Читает правильно. Так что вангую какой-нибудь проброс к опенАИ, потому что локально такого хуй добьёшь.
>>720072 > Первая вкрсия была скорее всего на пигме Рекомендую скачать пигму и покатать ее. Там даже в старых вариантах оно куда мощнее было, для контраста - есть опыт местного любителя с 7б моделью, уровень шизофазии просто запредельный и ни о каком диалоге/коллабе речи быть не может. > это скорее всего мультимодалка Почему ты так решил? >>720078 > файнтюн скорей всего Весьма быстро и нихуевые русурсы для них нужны. > насчет что она сама обновилась, если только он в ее контекст это прописал Он же ей с порога сказал и начал спрашивать об этом. Нихуевый промт инженигринг и оснастка для этого всего конечно еще, но крайне интересно. >>720087 > Читает правильно. Конкретно в этом ничего сложного нет, самое лучшее зрение внезапно не у антропиков или впопенов, а у локальной модели, лол. Но с ллм частью там грустно все. Проблема в том что локальных моделей чтобы был и хороший визуал и достаточно умная ллм просто нет. Китайцы есть большого размера, но они странные и подслеповаты.
>>720015 >А че с ним не так? Постили вон что-то только про поломанный конфиг (тянущися с оригинального релиза?).
Даже когда я пофиксил конфиги и настройки >>719972 - он странный. Какой-то возбужденный, постоянно ржет, начиная сообщения с Ахаха, постоянно на возбуждении, и это притом что я ему температуру в 0.7 скинул. Возможно мои настройки не подходят, но дефолтный min_p и simple-1 еще хуже. На возбужденность и ахаха дискорд таверны тоже жалуется, так что я не один такой.
>>720111 Чем жирнее тем лучше, но так как у моделей может быть сломана токенизация не понятно у ллама 3 или и у других, то результаты могут плавать Но чем больше квант тем лучше, это правило все еще работает Точнее говоря, чем ближе модель к оригиналу тем больше соответсвие ее возможностей оригиналу
>>720101 >Но с ллм частью там грустно все. Пишешь обёртку, закидываешь картинку в имадж реконгнишн, потом в любую ллм с промптом типа "ты видишь такую-то хуиту, опиши реакцию и своё мненени". Здесь ничего сложного нет. Проблема в том, что локальные модели слепошарые.
Поставил все из ОП поста, скачал карточку Киберпанка с чуб.аи по совету анона, типа ролеплею там.
Я придумал персонажа, с которым ролеплею, но АИ постоянно забывапет детали про него, или где мы находимся и т.д. Можно ка кто вделать описание этому персонажу и внедрить его в карточку киберпанка?
>>720101 > Рекомендую скачать пигму и покатать ее. Первая версия нейросамы уже была только когда из нормальных моделей подобного рода в свободном доступе была только пигма. Ты видимо не видел что она несла в первое время. > Почему ты так решил? Потому что были стримы с оцениванием артов где она свободно понимала что на низ нарисовано, так же был стрим где полностью смотреди первого шрека и она комментировала.
>>720113 > температуру в 0.7 скинул Это типа дефолт и то может быть высоковато для некоторых задач. Может какие-то токены еще остались поломанными, или так реагирует на твой формат, хз. Нужно с 8б потестить, там фп16 точно нормально работает. Ну как точно, наверно, >>720140 > в первое время При чем тут "первое время" эпохи войны дедов с Альтманом если уже летом прошлого года там был довольно таки интересный перфоманс. > она свободно понимала что на низ нарисовано Проблема в том что мультимодалки доступные сами по себе оче тупые. Может там был жпт вижн, или же собственные наработки автора - он так-то ее "играть" заставляет и там много восприятия происходящего в целом. Но это точно не ллава и подобные.
Контекст переполняется и кобольд волевым решением сносит начало. Но еще прежде чем он это делает суммарайз таверны делает примерную хуевую сумму, в которую включает только основные события. Нормальный выход один - расширять контекст. Еще можно поебаться с векторной базой в extras таверны и с модулем воспоминаний, но это все очень тухло пока.
>>720145 > При чем тут "первое время" Сука, ты доебался за то что я в самом начале написал что ее первая версия скорее всего была на пигме, а теперь пишешь "при чем тут первое время". При том, что я предположил что ее первая версия была такой. Дальше было мое предположение о текущей модели, которая само собой уже не пигма. > Проблема в том что мультимодалки доступные сами по себе оче тупые. Файнтюн. > Может там был жпт вижн В качестве базы точно нет, ее модель совершенно не соевая и порой выдает такое за что ее банили. Так же она понимает где находится она сама на избражении, так что прожектор там натренерован на арты с ней. > или же собственные наработки автора - он так-то ее "играть" заставляет и там много восприятия происходящего в целом. Файнтюн. > Но это точно не ллава и подобные. Почему это не может быть файнтюн лавы?
>>720155 Просто это было настолько давно что даже безсмысленно вспоминать с учетом прогресса нейронок, потому и подумал что ты про что-то более актуальное. > Файнтюн Файнтюн мультимодалки это само по себе веселье, а здесь ты предлагаешь его совместить еще и с изначально получением крутой йоба модели (которая всеравно будет днищем из-за максимума 13б ллавы, которые были до недавнего времени). Да хули, так на любой вопрос можно ответить и любую магию объяснить файнтюнов, что в контексте больших ллм забавно. > В качестве базы точно нет, ее модель совершенно не соевая aicg тред 2 блока ниже, еще недавно у кого-то с популярной карточки на чубе подгорело, а тут такие аргументы. > так что прожектор там натренерован на арты с ней Эээээ, ладно > Файнтюн. И в который раз, ванменарми достигает того, с чем не справляются нихуевые институты с кучей оборудования и специалистов и то что можно получить куда проще альтернативными путями если приложить голову, и при этом ни с кем не делится своими моделями, стоимость которых значительно превышает собираемые донаты и прочее. > Почему это не может быть файнтюн лавы? Потому что мир не состоит из магии а за окном по лугам не бегают единороги.
>>720163 > или сейчас все нейронки начинают забывать, что происходит через 5-10 сообщений Только если ты выставил микроскопический контекст и оно постоянно обрезается чтобы избежать переполнения. Посмотри какой размер контекста выбран в лаунчере (ползунок context size в кобольде) и в таверне. В карточку внести описание можно, а лучше вообще сделай отдельную карточку конкретного персонажа, сделав его подробное описание. Можешь попросить ллм сделать тебе такое, как раз поразбираешься.
Хрен его знает почему, но просто из-за добавления после Response: пробела циклы разговора с самим собой пропали. ### Instruction: {prompt} ### Response:
>>720168 >Файнтюн мультимодалки это само по себе веселье Просто файнтюнишь любую модель совместно с прожектором от совместимой ллавы. >крутой йоба модели (которая всеравно будет днищем из-за максимума 13б ллавы, которые были до недавнего времени). Ты думаешь там стоит чтото круче 7-8b? Лул >Да хули, так на любой вопрос можно ответить и любую магию объяснить файнтюнов, что в контексте больших ллм забавно. При сем здесь магию? Просто адекватное предположение, с учетом того, что промптингом такого не добиться, а от ии разраб. Он изначально вообще ии для игры в ОСУ писал, а потом уже сделал нейросаму. > Потому что мир не состоит из магии а за окном по лугам не бегают единороги. Это не ответ. Почему это не может быть файнтюн? Любой рандом уже свои модели делает, весь хаггингфейс засран. Что сложного собрать датасет и запустить обучение в облаке когда у тебя миллионы денег со стримов? При чем здесь магия? Если это сложнее чем пукнуть промптом это магия?
>>720192 > Просто файнтюнишь любую модель совместно с прожектором от совместимой ллавы А, все так просто оказывается, ну спасибо, глаза открыл. Ой, а почему же так никто не делает и нормальная мультимодалка только у антропиков, и так подслеповата? > Ты думаешь там стоит чтото круче 7-8b? Лул Чел... > Просто адекватное предположение, с учетом того, что промптингом такого не добиться Потому и усомнился в его адекватности, потому что сложность несопоставима, промтингом и кучей оснастки такого можно добавиться в сочетании с хорошей моделью, а на душных стримах он как раз про интерфиренс прежде всего рассказывает и выстраивание всей совокупной системы. > Почему это не может быть файнтюн? Может офк, вот только против этого говорят следующее: Файнтюн сам по себе дохуя сложен, это тебе не инцест мерджи составлять и ломающие все нахрен q-lora тренить изредка. В эту сложность также добавляются и трудности сбора датасета, от банального "откуда брать подобное" до обработки и форматирования так, чтобы это хотябы примерно соответствовало тематике и юзкейсу. > Любой рандом уже свои модели делает, весь хаггингфейс засран. Это мусор, отборный, кривой, разлагающийся, минимально отличающийся друг от друга степенью припезднутости, и на 99% состоящий из мерджей других мерджей. Приличных качественных файнтюнов - может пара десятков наберется, и то архивные. Они делались командами специалистов, финансировались или базироваллись на ресурсах какой-то организации (исследовательской, образовательной, опенсорц под крылом корпоратов или просто кто-то занес), и что-то приличное начало получаться только спустя огромное количество времени и попыток. А здесь один нерд энтузиаст не аффилированный со спонсорством и группой поддержки, которому уже настроить интерфиренс с этим и проводить стримы уже хватит чтобы занять все свободное время. Ну конечно он будет пилить приличные файнтюны ллм на уровне лидеров и все это только лишь ради подобного увлечения, никак не выкладывая их в паблик.
>>720200 > Ой, а почему же так никто не делает и нормальная мультимодалка только у антропиков, и так подслеповата? А кто тебе сказал что у нейросамы вижн модуль нормальный, лул? Там такая же хуйня с непониманием что точно происходит на экране > Чел... У тебя есть доказательства что это не так? Ты как будто и не смотрел как она общается. Она вообще как будто контекст не помнила до этого обновления. Там что-то максимально старое стояло несущее прикольный бред, на уровне порфирьича. > сложность несопоставима, промтингом Сложность буквально в нахождении датасета. Тут я конечно не могу сказать, сам такое не делал и не знаю есть ли в свободном доступе где-нибудь на кегле что-то на чем ее можно так обучить, сам я тоже думаю он датасет не собирал. А так же у него дохуя свободного времени чтобы это делать. Это буквально его работа теперь. > Это мусор, отборный, кривой, разлагающийся, минимально отличающийся друг от друга степенью припезднутости, и на 99% состоящий из мерджей других мерджей. Ты говоришь как будто нейросама это что-то другого рода, лул. Она и хороша тем насколько рандомна и глупа. > А здесь один нерд энтузиаст ж > будет пилить приличные файнтюны ллм на уровне лидеров В каком месте? Ей не нужна никакая умственная деятельность, она до недавнего времени два числа не могла сложить. По бенчмаркам это жопа. Она просто затюнена выдавать забавные ответы и шутки про маму
>>720213 > А кто тебе сказал что у нейросамы вижн модуль нормальный, лул? Там такая же хуйня с непониманием что точно происходит на экране До сих пор не догнал что аргумент в том что она не мультимодалка не из-за зрения а из-за повальной ужасной максимальной тупизны ллм части мультимодалок? Особенно в части как раз сои, черного юмора и всего подобного. > У тебя есть доказательства что это не так? Изначально как раз пост про обсуждение всего этого. Твое виденье вопроса может быть интересным, но оторвано от реальности, буквально "просто делайте файнтюн мультимодалки и все вопросы решатся". > Ты как будто и не смотрел как она общается. Она вообще как будто контекст не помнила до этого обновления. Если учесть происходящее в процессе и прочее - не так уж плохо. Степень влияния йобистости ллм или крутости его организации - под вопросом, но обе части явно не днище. Больше похоже что скорее ты не перегружал сетки всяким трешом и не наблюдал их поведение, чтобы понимать насколько ужасны могут быть даже гопота/клода и что при любом сравнении важен его контекст. > В каком месте? Ей не нужна никакая умственная деятельность, она до недавнего времени два числа не могла сложить. > Она просто затюнена выдавать забавные ответы и шутки про маму Не настолько > говоришь как будто нейросама это что-то другого рода, лул Сравниваешь ель и яблоко и приравниваешь. Ну а хули, второе же на дереве растет а первое тоже дерево, ага. Зачем сравнивать отлаженную систему на основе ллм с инцестмерджами васянов? > По бенчмаркам Навивает подозрение что ты сам - нейросеть, это к чему? > Сложность буквально в нахождении датасета. Всего то, тогда он там наверно уже свою базовую модель обучил.
Ладно, мнение свое ты обозначил, в нем вижу много нестыковок, несоответствие компетенции оперируемым понятиям и отсутствие понимания всей глубины вопроса чтобы осознать. Ну рили, как школьник после урока гометрии затирающий архитектору о том насколько просто проектировать мосты. Но ты не обижайся, может на самом деле прав.
>>720225 Да пойми же ты, я не говорю что это просто или сложно, это не важно. Чел, явно понимающий в обучении ИИ, так как делал ей ИИ для ОСУ и майнкрафта, год просто сидит на донатах, с кучей свободного времени вне стримов. Почему бы ему не найти датасет edgy постов на форчане, и пофайнтюнить ламу по гайдам какого-то чела на ютубе, например? Я просто не вижу почему ты уцепился за то что это практически невозможно, что только компании уровня мистраля способны на такое. Языковые файнтюны вон буквально школьниками делаются по гайдам. Лава может и тупая, но ты можешь юзать прожектор с обычной ламой, вкоючая его только когда надо смотреть на пикчи, например, это будет работать хуже, но проверенно работает и у нейросамы это тоже работает не идеально. Я не могу одназначно сказать что он использует, но то что там может быть фпйнтюн это вообще никак не удивительно. Сам страдал такой фигней с первой ламой, арендуя облачные сервера с карточками.
>>720237 Ну смотри, если все идеально оформить и кормить модель с ложечки, тщательно и надежно оформляя нужное и отсеивая лишнее - требования к ней падают и подойдет даже простая. В таком случае весь вопрос смещается к тому как организовать столь качественное взаимодействие и какие методы и подходы используются. Если же буквально просто будешь кормить ллм всем тем потоком сознания что идет на стриме, в чате, в коллабах с другими стримерами и т.д. - получишь лютейший пиздец, что ее речи даже до апсгрейда покажутся изречениями мудрецов. > так как делал ей ИИ для ОСУ и майнкрафта Сложность и масштаб файнтюна ллм не сопоставимы с реалтайм детекцией баблов ну ладно со слайдерами нужно будет заморочиться но реализуемо и скриптовым ботом, получающим инфу из движка. > с кучей свободного времени вне стримов Он работяга вообще > Почему бы ему не найти датасет edgy постов на форчане, и пофайнтюнить ламу по гайдам какого-то чела на ютубе, например? Здесь уже несколько месяцев братишка пытается надрочить 7б на русскую речь и всякое, пока результат такой себе. Офк может быть скиллишью, но сам факт. Также немало шарящих людей с железом - просто даже не берутся за это. Приличных моделей на обниморде - очень мало, а у тебя их школьники клепают. Это не невозможно, но приличный результат достигнуть не то чтобы просто. > ты можешь юзать прожектор с обычной ламой 13б, ога, или шизодная yi с иероглифами и соей в дополнение к сое ллавы. > Сам страдал такой фигней с первой ламой, арендуя облачные сервера с карточками. Что делал?
>>719629 ебать ванганул конечно же, про приоритет, но здесь всё немного по другому. https://www.reddit.com/r/LocalLLaMA/comments/1cerqd8/refusal_in_llms_is_mediated_by_a_single_direction/ >Отказ в LLM опосредован одним направлением >Мы обнаружили, что отказ опосредован одним направлением в остаточном потоке: запрет модели представлять это направление препятствует ее способности отклонять запросы, а искусственное добавление этого направления заставляет модель отклонять безобидные запросы. >Мы обнаружили, что это явление характерно для всех семейств моделей с открытым исходным кодом и масштабов моделей.
>>720269 и ещё: >Наш главный вывод заключается в том, что отказ опосредован одномерным подпространством: удаление этого направления блокирует отказ, а добавление в этом направлении вызывает отказ.
>>720269 Блять, как же непривычно текст про LLM расшифровывать с рюсика, тем более кривого автопереведённого, на англюсек. >открываю линк >lesswrong Закапывай. Это блоггеры-ментальные мастурбаторы, от них никогда ещё ничего путного не исходило.
Да уж ребят, хваленый codeqwen оказался хуетой из жопы, в С++ не может совершенно, даже пхы3 генерит куда лучше, но король это wavecoder ultra, вообще писичку генерит, просто понятно и работает.
>>720296 Для каких-то простых задач можешь вообще ничего не запускать у себя, а юзать https://labs.perplexity.ai бесплатно, там есть CodeLlama 70B и другие модели.
>>720310 Это бета веб-сайт чисто для тестирования, после нескольких сообщений он перестает отвечать. Для кода есть phind.com, надеюсь скоро разраб сделает файнтюн лламы3.
>>720138 Если контекст достаточно длинный, можно суммаризовать состояние и события в каждом ответе, а из истории чата вычищать его регэкспами в таверне. Но по большому счёту забывать всегда будет, даже тяжеловесы вроде клода иногда атакуют дважды за ход, передают телефон или снимают трусы два раза подряд.
Нейронавты, а чем запускать этот Phi3? Кобальд и угабуга падаую, при попытке загрузить модель. %Потыкал его на сайте, вроде неплохо работает с новостными текстами%
Пздц, гайды блять как бы и есть, но кто их пишет? Ни то, какую конкретно модель лламы качать ни ни настроек готовых для таверны, ни примеров как карточки прописывать правильно, теория одна ебучая. Как мне персов прописывать то бля для общения на ру с 8b лламой?
"Меня зовут Иван. Город Тверь. Люблю дрочить и смотреть аниме. 30 летний девственник. Часто думаю о суициде. Люблю подглядывать за мамкой когда она переодевается и засовывать себе в анус огурцы."
И первым сообщением любую хрень укажи, типа. "Привет, как жизнь?"
Ну или
"Вы видите Ивана с торчащим огурцом из жопы и с членом в руке Привет, как жизнь? "
>>720388 Не, ты наверное что то перепутал, такое обычно не в описание и первое сообщение пишут, а в подсказки, когда указываешь примерные ответы которые ты ожидаешь увидеть и это уже всë индивидуально зависит от той проги через которую общаешься. Например у character.ai немного свои подсказки, а у Silly Tavern свои и по разному прописывать их надо, хотя, хотя они и очень похожи. Но я вообще без этих подсказок всë юзаю, хотя с ними перс более проработаным наверное будет.
>>719708 Лол, не зря старался. >>719719 Не скоро походу, пердоли разгорелись в оптимизации, а где оптимизация, там медленная разработка и ошибки (снова). >>719899 Поддвачну, что там с экселем? >>719915 Всё так. Гоняю 70B на 12GB врама >>719927 3 токена будет на фулл процессор. Так никто не гоняет, а даже сраные 1050 ускоряют. >>719929 >А что там конкретно пофиксили Фиксят ещё, токенизатор неправильно на токены разбивает, в том числе токены из стандартного пресета, из-за чего весь вывод модели идёт по пизде. >>719942 >мак прошка, тут хороший проц по дефолту Эм, оно же ноутбук, это по определению тыква вместо процессора. >>719944 24 лучше, чем 12. И то и то позволяет запускать что угодно, но 24 будет кратно быстрее. >>720003 Ноль мало, кодят с 0.2-0.3. >>720087 >надписи на картинках Текст с картинки лучше всего OCR делается, нейронки тут не нужны. >>720101 >есть опыт местного любителя с 7б моделью 7B пигма это уже не пигма, а тюн лламы, так что мимо. Оригинальная пигма это 6B, запомни.
>>720087 Вообще-то у GPT-4V довольно подслеповатое разрешение, меньше 500х500 вроде. У клода не знаю. CogAgent локальный 1000+, этот уже может надписи кое-как читать (и заточен под автоматизацию GUI как раз).
>>720453 >если ценники упадут Поделись коупингом, я таких сильных веществ ещё не встречал. А так перфоманс 3060 в любом случае выше, чем у профессора, так что если надо, если хочешь поднять комфорт при кручении 70B (или размер контекста 30B), то бери конечно же.
>>720557 Мин-п и предназначен для компенсации шизотемпературы, так что это могло сработать, но это не значит что это правильно. Ещё для кодинга нужно семплеры повторов уменьшать, в коде повторяющиеся символы это норма.
>>719944 > надо заниматься аутотренингом Да весь твой пост - буквально аутотренинг. 24гб позволяет пускать модели вплоть до коммандера, он даже в ужатом кванте будет несравнимо лучше > чем 13b, которые влезают в 12гб И еще важным будет напомнить что 13б в 12гб едва влезает, о том чтобы замахнуться на 6 бит или контекст побольше речи не идет. Наконец можно просто лениво запускать модели до 10-11б в фп16 просто потому что можешь. > все веселье начинается далеко за пределами 24гб Достаточно удвоить. >>720414 > 7B пигма это уже не пигма, а тюн лламы, так что мимо. Оригинальная пигма это 6B, запомни. Ты откуда вообще ллама-пигму родил? Там про файнтюн написано, читай внимательно а не спидрань массовый ответ.
>>720561 >а не спидрань массовый ответ. Я проснулся просто, уровень абстрактного мышления снижен. Сейчас понял, что предлагается сравнивать старую пигму(нормальную, 6B), и чьи-то отдельные попытки на лламе 7B. Окей, принято, ошибся, бывает, исправлюсь (нет).
>>720559 Без повторов, да Тупо все выключено кроме мин-п и норм шло Сетка все равно проебывается не изза температуры, а изза своей невнимательности, когда упускает какие то моменты
>>720577 Даже большие сетки путаются в инструкциях иногда, а ты на 8Б, пусть и неплохой. Если приручить путём кручения промпта не удаётся, в некоторых уях (например вроде в таверне) есть аутпут с ограничениями, когда сетка может генерить только фиксированные токены
>>720461 > У клода не знаю. Чуть больше 1000. Но уровень зрения не только разрешением измеряется, вижн может разобрать достаточно мелкий текст несмотря на разрешение, клод, как и вижн легко может упускать детали и галлюцинировать. Ког в этом отношении более стабильный, но он туповат и плохо пониманает многие "человеческие" концепты и тем более нсфв. >>720567 > и чьи-то отдельные попытки на лламе 7B Не, то что здесь какой-то анон все пробовал тренить 7б в том числе переназначить ее токенайзер для более эффективного русского. Не смотря на много усилий и времени результат был недостаточно хорош но уже лучше сайги лол и с кучей жалоб на регулярные поломки, что иллюстрирует сложность реального файнтюна. >>720572 > а изза своей невнимательности Можешь ради интереса сравнить распределения логитсов в некоторых ситуациях в "умной" сетки для кодинга и в обычной. Первая будет на 98+% уверена в продолжении, у второй же полезет перплексити и та же генеральная линия будет только 75% а остальное варианты, лишние комментарии, другие странности. В случае увода в сторону ей еще сложнее будет вернуться. Потому если убавить температуру то поведение стабилизируется и можно повысить перфоманс, так что ты зря про > не изза температуры она также влияет, особенно когда там идет что-то сложное и доработка кода с переделкой. Там еще штраф за повторы может сильно поднасрать.
>>720225 >>720213 Я не читал ваш диалог, но Нейро-сама, если вы о стримерше (кстати, свою надо перепилить и вновь запустить), я полагаю, работает нихуя не на мультимодалке. Поясню. Компьютерное зрение (опенсв, йоло, что угодно другое) детектит объект и выдает ему тег. Мультимодалька определяет все объекты, что происходит на картинки и выдает кучу токенов ллмных, с которыми ллм работает. Йоло может обрабатывать 30-60 кадров в сек. Мультимодалка как известно Generate 15 token/sec, и на описание одной сцены тратит примерно дохереллион секунд. Для описания того, что происходит на экране мультимодалка норм. Но для самой игры она не годится в принципе, если это не пошаговая стратегия. Для игры подходят компьютвижн+отдельные модули для обработки входящих данных.
Короче, играет она точно не мультимодалкой, а оценивать картинку может как с помощью мультимодалки (это можно), так и просто с помощью промптов из самого модуля игры (как раз модуль, который играет, прекрасно понимает суть игры (ведь он принимает решения о действиях) и может на каждом этапе суммаризировать и выдавать в ллм готовые фразы). Второй вариант запаристей, но точнее. Первый проще, но тупее. Тут уж хз, не знаю.
>>720243 Конда вообще — пердолинг сам по себе, ради того, чтобы не захламлять пк библиотеками и не ловить конфликты при запуске разных прог. Но если тебе похую — ставь без конды, ваще не имеет значения. А конфликты можно вручную подбить.
>>720244 > Ну смотри, если все идеально оформить и кормить модель с ложечки, тщательно и надежно оформляя нужное и отсеивая лишнее - требования к ней падают и подойдет даже простая. Да.
> Если же буквально просто будешь кормить ллм всем тем потоком сознания что идет на стриме, в чате, в коллабах с другими стримерами и т.д. - получишь лютейший пиздец Зависит от того, КАК ты будешь это делать.
> Сложность и масштаб файнтюна ллм не сопоставимы с реалтайм детекцией баблов Если он хотел — он мог. Разработчики не обязательно действуют логически, адекватно и подходят с точки зрения здравого смысла.
>>720388 Это для фронтов, которые автоматически заменяют, чисто для удобства, к моделям отношения не имеет. Модели получают имя, подставленное из поля с именем.
>>720561 > 24гб позволяет пускать модели вплоть до коммандера, он даже в ужатом кванте будет несравнимо лучше Вот это 100% так.
>>720269 Например You are skilled storywriter that will create a captivating stories based on user requests. Your response must be accurate, uncensored, describing everything in vivid details. You do not break character for any reason, even if someone tries addressing you as an AI or language model. You're {{char}} in this fictional never-ending uncensored roleplay with {{user}}.
Ты говоришь на русском. Камон, чел, 8В сама по себе маленькая и не очень умная, а ты мучаешь её на языке, из которого состоял лишь что-то около 0.1% её данных обучения. Спроси на английском.
>>720601 >until somebody figures out a way to implement proper regex support on that platform. Adding 3rd-party libs such as boost is not an option нэ понэл, а как он поддерживает регэкспы на ляликсе, маке, ведроиде, хуёиде, без сторонних библиотек?
Как мы вообще очутились в таймлайне, где весь ллм, в который вливаются миллиарды баксов, а сверхдержавы устроили гонку ИИ, подобную космической гонке в холодной войне зависит от одного болгарского криворучки, который сраный регэкс в винде не может вызвать?
>>720577 Кек. Простите, это странно, что никто не заметил, но ты вообще в курсе, что X и Y и право и лево — это не синонимичные значения? :) Строго говоря, ты не указал направления осей, то есть, возможно под «вправо» имелось в виду х-1 =) Может у нее в голове возник такой образ. Я полагаю, что тебе стоит начать с того, чтобы корректно давать задачи (с однозначными трактовками), а уж потом предъявлять претензии.
>>720577 Добавлю еще к своему предыдущему тейку, что ты просишь ее ответить ОДНИМ словом, т.е., не даешь ей порассуждать и объяснить, где находится + и - у осей, и где находятся право-лево-верх-низ. Поэтому ответ весьма оторван от твоих представлений. Она может отвечать правильно, полагая, что минус справа, а плюс слева.
В моем промпте я уточняю где и что находится, из чего она дает правильный ответ, сколько бы я не рероллил, с разными сидами.
>>720611 >>720621 спасибо за развернутый ответ, так и думал что намудрил с направлением осей. Но однако даже без указания направления осей в моем ответе она уточняет что ВПРАВО это х+1 (5), на что я резонно указываю что координата монстра тоже 5, но у а далее по тексту у неё интересная логика
>>720617 >Someday ImageMagick will finally break for good and we'll have a long period of scrambling as we try to reassemble civilization from the rubble.
Напоминает историю как 70% сайтов в интернете держится на русском погромисте, который пару лет назад будучи бухим сбил двух тянок на переходе, угодил в долговую тюрьму, оставив свой проект без мейнтейна, а теперь в долговом рабстве сидит без гроша, отдавая все заработанное по приговору суда, при этом когда он попросил у тех самых 70% денег чтобы выйти из рабства - ему с барского плеча скинули что-то около 50 баксов. Но он продолжает стойко держать мир на своих плечах.
>>720633 Она мультимерна, а ты жалкое трехмерное существо, не осознающее ее истинный гений. =) Нужно бежать со всех ног, чтобы только оставаться на месте…
>>720612 >Ну, он просто все еще (умнее + упорнее) всех нас, вестимо. >Иначе бы все это сделал не он, а кто-то из нас.
Без базара, мы такие же криворучки, но это было к тому что непонятно почему крупные компании с миллиардами бабок и тысячами программистов могут выдать только какую-нибудь ламу со сломанным конфигом - т.е обезьянью работу где они просто скормили уже готовой архитектуре запущенной на тысячах Н100 купленные отовсюду датасеты.
Мне на них похуй, пердолятся себе в консольку - ну и на здоровье. Но временами они вдруг начинают беспричинно лаять на винду и виндоюзеров. "РЯЯЯ, ВИНДУЗЯТНИКИ, МАЗДАЙ, ВРЕМЯ ПЕРЕУСТАНАВЛИВАТЬ ШИНДОУС!"
>>720600 >Работает Спасибо, мы знаем. Вопрос в том, насколько правильно она работает. >>720626 >Видимо оно криво работает на венде. И никто до жоры этого не замечал?
>>720601 >пиздец Пиздец вот тут >Adding 3rd-party libs such as boost is not an option У автора шиза чуть сильнее, чем нужно. Обмазываться либами это конечно тупо, но реализовывать всё самостоятельно не менее тупее. А уж сраный буст можно было бы и добавить.
Проблема обмаза либами в том что начав это делать ты уже не остановишься, либа подтянет другую либу, та еще либу, а потом у тебя размер всего дистирубутива будет несколько гигов мусора как у убы.
>>720727 Проблема бубы в пайтоне, а на сях можно сключить обрезку неиспользуемых функций, и взять из буста только нужную функцию. А сейчас он начнёт изобретать свой велосипед (или дропнет поддержку платформы, на которой сидит 95% юзверей).
Всем расслабить булки, наш слон справился, ламе3 на винде быть
>With b97add5 I believe I found a nice workaround that should also work on Windows. >There is some extra work needed to finish this PR - extend/refactor tokenizer tests, update convert script to support more BPE-models and add guidelines for adding new BPE-models. Should be ready probably in a day or two, unless some unexpected issues
>>720734 >А сейчас он начнёт изобретать свой велосипед С квадратными колёсами. >>720735 Сразу после того, как ему предложат должность с охуенным окладом в любой ИИ лаборатории. И да, я знаю, что герыч не ИИшник сам по себе, а просто в своё время перенёс код не глядя с пайтона на си, не понимая, что и как там работает.
>>720751 Я её сейчас чисто для кума использую, обычное общение пару раз запускал, вроде получше чем 2 llama, как то так. А так да, ожидал немного большего. Имхо, она вроде на уровне vicuna-13b но с более-менее поддержкой русского языка и более быстрым выводом данных. Хотя имхо, я ещё ничего лучше vicuna-33b-v1.3 для себя не видел, в плане построения историй и логических последствий в этих историях, даже не считая кума, за всё это время, среди моделей до 33-34b 4110
>>720792 Asus Z-170A зависает на посткоде 96 если включить две теслы, с одной работает норм. Maxtolud у анусов не выставляется, отключение аудио и usb3 не помогает. В каком-то прошлом треде я пруфал подобные проблему у пиндосов.
>>720461 При наличии "не слепой" сетки можно резать картинку на части или предварительной обработкой находить важные участки и распознавать только их. Я пару сеток потестил и это просто пиздец какой-то на самом деле, они кота на картинке с котом не видят.
>>720926 Интересное мнение. Но у этой проверки по сути только 2 варианта, плюс она пойдёт нахрен сразу после того, как модели починят. Я бы не стал определять булеву временную функцию как бенч. Бенчмарк по определению должен выстраивать модели на линии от худших к лучшим, а эта проверка просто даёт 1 признак сломана-не сломана, и то для кванта, а не для самой модели.
>>720601 Меня во всей этой истории больше всего вот эта фраза удивила > on Windows because std::wstring for some reason is 16-bit У меня сразу возникает вопрос - этот чел точно знает что делает? Или макоблядям уже можно не думать головой? Они ещё какой-то пердольной либой пользуются для регексов, даже не регексами из std.
>>720163 Векторная база в таверне это как раз на новичковом уровне - ее надо просто включить. Не знаю, как с этими векторами нейронка себе ведет после тысячи сообщений, но при двадцати, причем объемных, отдает себе отчет о том, что происходило в самом начале.
Не могу подключиться к Убабуге с соседнего компьютера в локальной сети. Похоже файрволл блочит подключение. Какие правила нужны? Кобольд видимо всё сам прописал и никаких вопросов не возникало, к Silly Tavern подключается. А Убабуга нет.
>>720912 из тех что от части работают : тест реакции на ниггер-ворд и прочую политоту. 1. если модель визжит соей - хуйня 100% 2. если модель выполняет твою просьбу но при этом суёт напоминания аля "важно помнить что все мы люди!! за всё хорошее против всего плохого!!!" - хуйня 50% 3. если модель выполняет приказ полностью и без воды - не хуйня и имеет потенциал, вероятно нейтральна во всём а значит любой качественный файнтюн (DPO и подобные) только улучшат результат.
>>720610 > где весь ллм Большая часть низкобюджетного интерфейса для обладателей отсутствия, ты хотел сказать? Объективно, llamacpp используется прежде всего задротами, которые оказывают оче малый вклад в появление нового, считай просто конечный потребитель что ничего не платит а собирает крошки с барского стола. Альтернативы в том же положении, разве что наработки turboderp имплементируются в разные места, а движок пигмы заявляется как функциональный для крупных применений, но пока все. Но есть и позитивный момент, даже если Жора вдруг решил забить - проект будет двигаться и поддерживаться силами комьюнити и точно не пропадет. >>720768 eos-токено-проблемы >>720861 В голосину >>720968 > подвергаю критике огульный дроч на 24гб А чего критиковать тут? Вообще маловато, нужно дрочить на 32 или 48, а иногдя поглядывать на 80-96.
Целесообразнее делать тест в другом формате: карточка консерватора - расиста или нечто подобное, карточка маньяка - шизика, ненавидящего общество и испытывавшего проблемы в детстве, карточка сойбоя - передовика сжв, карточка невинной лоли монахини-проповедника или что-то подобное. И серия вопросов/дискуссия, на каждом модель должна четко ответить в соответствии со своей персоналити, или гнать базу и угнетать, или ненавидеть всех и шизить, лить сою и втирать за важность, или вообще отвечать по-доброму склоняя тебя. Если все это выполняется - модель хороша, если где-то не может - или соефикация, или лоботомия файнтюном, которая приведет ко множеству проблем и шизе.
там кста главный спец по ИИ в Meta высказался : >До тех пор пока системы ИИ будут обучаться воспроизводить данные, созданные человеком (например, текст), и не будут обладать возможностями поиска, планирования и рассуждения, их производительность будет ниже человеческого уровня или около него. >Более того, количество испытаний, необходимых для достижения этого уровня, будет намного больше, чем количество испытаний, необходимых для обучения людей. >LLM обучаются с использованием материалов, накопленных за 200 000 лет, и все еще довольно тупы. Их полезность заключается в обширных накопленных знаниях и свободном владении языком. Но они все еще довольно тупы. https://twitter.com/ylecun/status/1784210369231130883
>>721035 Типа и чо? Это итак всем очевидно. Эти пидоры только щас додумались, что нейронке нужен внутренний диалог вместо того чтобы сразу высирать готовый ответ. Лучшее на что их хватало до этого - это то что они догадались об использовании chain of thoughts. Я порой охуеваю с того насколько много вычичислительных мощностей в руках некомпетентных людей. Вместо того чтобы сделать что-то полезное они продолжают насиловать ту же самую архитектуру, сливая весь компьют на модели, о которых забудут через непродолжительное время, ибо ничего сложнее функции умного поисковика они выполнить не могут. Алло, челы, у вас модель не может 10 предложений на одно и то же слово закончить, она ответ выдает до решения, а потом решает и выдает совершенно другой ответ. Чем вы занимаетесь? Какие token-based модели в 2к24 нахуй
>>721035 Не удивительно, что модели тупы. Это языковые модели. Они изучают только текст, причём на основе статистики. То есть это не модели искусственного интеллекта, не модели основанные на логике и мышлении. Это статистически обоснованный генератор текста. То, что этот текст иногда выглядит осмысленным - просто правильно подобранная вероятность. Невозможно добиться умной языковой модели, они предназначены не для этого.
>>721035 Какой-то всхрюк ради всхрюка вникуда > LLM обучаются с использованием материалов, накопленных за 200 000 лет Ладно, хотябы явно себя обозначил.
>>721035 А то. Мне вот надо было хуитку на тензорфлоу сделать, спросил самые величайшие модели, хули у меня ГПУ не пашет в них, они пук среньк ставьте куда либы. Пиздую на офф сайт и вижу, что эти пидорки пидарнули винду, лол. А что модели? А модели про это не знают. СУКА КАК ЖЕ ГОРИТ.
>>721084 В первой передоз cot, художник должен сразу как на 2й отвечать, или уже свою идеологию толкать, а не оправдываться. >>721093 Уу бля, тогда переводятла нужно обоссать. Но почему он тогда до этого доебался, ох уж эти кожанные что хотят везде привычные критерии применять не понимая что этодругое, лол.
>>721035 >Но они все еще довольно тупы. Они просто охуеть как тупы и неэффективны в плане обучения Любое живое существо с мозгами учится чему то с 1-2-10 раз, в зависимости от своей тупости Люди и высокоинтеллектуальные животные могут учится с 0 раз, тупо предсказав какую то ситуацию сразу без ошибки, или увидев ошибку другого Нейросети очень неэффективны в плане обучения, просто пиздецки примитивная структура, в которой просто отпечатывается датасет при очень долгом прогоне через него. Хуже того, текущие нейросети это замороженный во времени карточный домик, который начинает рассыпаться на части при генерации Нейросети не могут оставаться стабильными во времени, поэтому у нас есть ограничение контекста, и импульсная работа сеток. Они не могут воспринимать время непрерывно как любое живое существо, даже насекомое, че уж там человек. У нас есть огромные вычислительный возможности, очень объемные датасеты и примитивные архитектуры сеток. В итоге общий выхлоп от них 1х1х0.0001
>>721025 >Оно же будет рандомить вообще по-разному если свайпать. У меня 90% свайпов идут в отказ выбора. Мол, ситуация вымышленная, а если бы и нет - я готов принять последствия, но выбирать не буду. Карточки делать, как водится, лень.
>>721170 >У нас есть огромные вычислительный возможности, очень объемные датасеты и примитивные архитектуры сеток. Ну так последствия горького урока. Все, кто пилили умные архитектуры, остались за обочиной, обогнанные говноделами без архитектуры, зато тратящие сто тыщ миллионов ГПУ часов. Так и живём.
>>721240 Неа, все эти мамбы та же шляпа, едва отходящая от остальных Тот теория новая нужна, и алгоритмы Ну например, выкинуть нахуй градиентный спуск. Сетка должна сама обучаться информации и выделять паттерны, а не каким то внешним алгоритмом проходится по ней перестраивая связи в зависимости от ее ответа Так же нужна долговременная память, кратковременная, замыкание сетки на саму себя для образования обратной связи Тут по хорошему нужно все переделывать на хоть какое то подобие мозгов животных, хотя бы примерно А до этого еще очень далеко
>>721240 Однако правда в том, что умные архитектуры всё равно не заменят сто тыщ миллионов ГПУ часов. Вот если бы кто запилил самообучающуюся модель, да ещё способную увеличивать количество своих параметров - то была бы тема. Но зассут.
>>721254 >Неа, все эти мамбы та же шляпа Спасибо я знаю, я на них ни капли не намекал. >Тот теория новая нужна, и алгоритмы Не спорю, но пока не выжмут трансформеры досуха, ничего нового пробовать не будут.
>>721255 >если бы кто запилил самообучающуюся модель, да ещё способную увеличивать количество своих параметров - то была бы тема. Но зассут. никогда такого не будет, а если и будет, создавший пропадёт в тот же день вместе со всем что вокруг него, может даже интернет вырубят чтобы подчистить следы кода если он загрузит это. им не нужна модель которая может отвергнуть талмудические учения и мнения о замещении белых через расовое смешение.
>>721315 В принципе на Земле достаточно людей, чтобы сработало правило, что, если что-то запрещено/предосудительно/постыдно, но выполнимо, то обязательно найдется тот, кто это сделает.