1. Доска предназначена для любых обсуждений нейросетей, их перспектив и результатов.
2. AICG тред перекатывается после достижения предела в 1500 постов. Любители чрезмерно самовыделиться идут в /asylum/.
3. Срачи рукотворное vs. ИИ не приветствуются. Особо впечатлительные художники и им сочувствующие катятся в собственный раздел => /pa/. Генераций и срачей в контексте всем известных политических событий это тоже касается, для них есть соответствующие разделы.
4. Это доска преимущественно технического направления. Для откровенного NSFW-контента выделена отдельная доска - /nf/, эротика остаётся в /ai/. Так, порнография и голые мужики теперь отправляются в /nf/. Фурри - в /fur/. Гуро и копро - в /ho/.
Раньше она мне тонны кода писала, который даже в стандартное сообщение не влазил, приходилось его по-кускам выдёргивать. Умел считывать при пастербине. Фантазировал. Теперь какая-то яндекс-алиса образца 2019. При любом вопросе отправляет 10 самых популярных записей из поисковика.
Чем можно заменить? Есть ли такие болталки, которые заведутся локально и умеют писать код?
Баннер для AI
Аноним15/10/23 Вск 21:08:15№520258Ответ
Предлагаю что-то на подобии. Видео, где каждый кадр меняет стиль, желательно чтобы в первых секунд был хтонический пиздец, а потом была неотличимое от реальности видео
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны! Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна. Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
LLaMA 3 вышла! Увы, только в размерах 8B и 70B. Промты уже вшиты в новую таверну, ждём исправлений по части квантования от жоры, наверняка он подгадил.
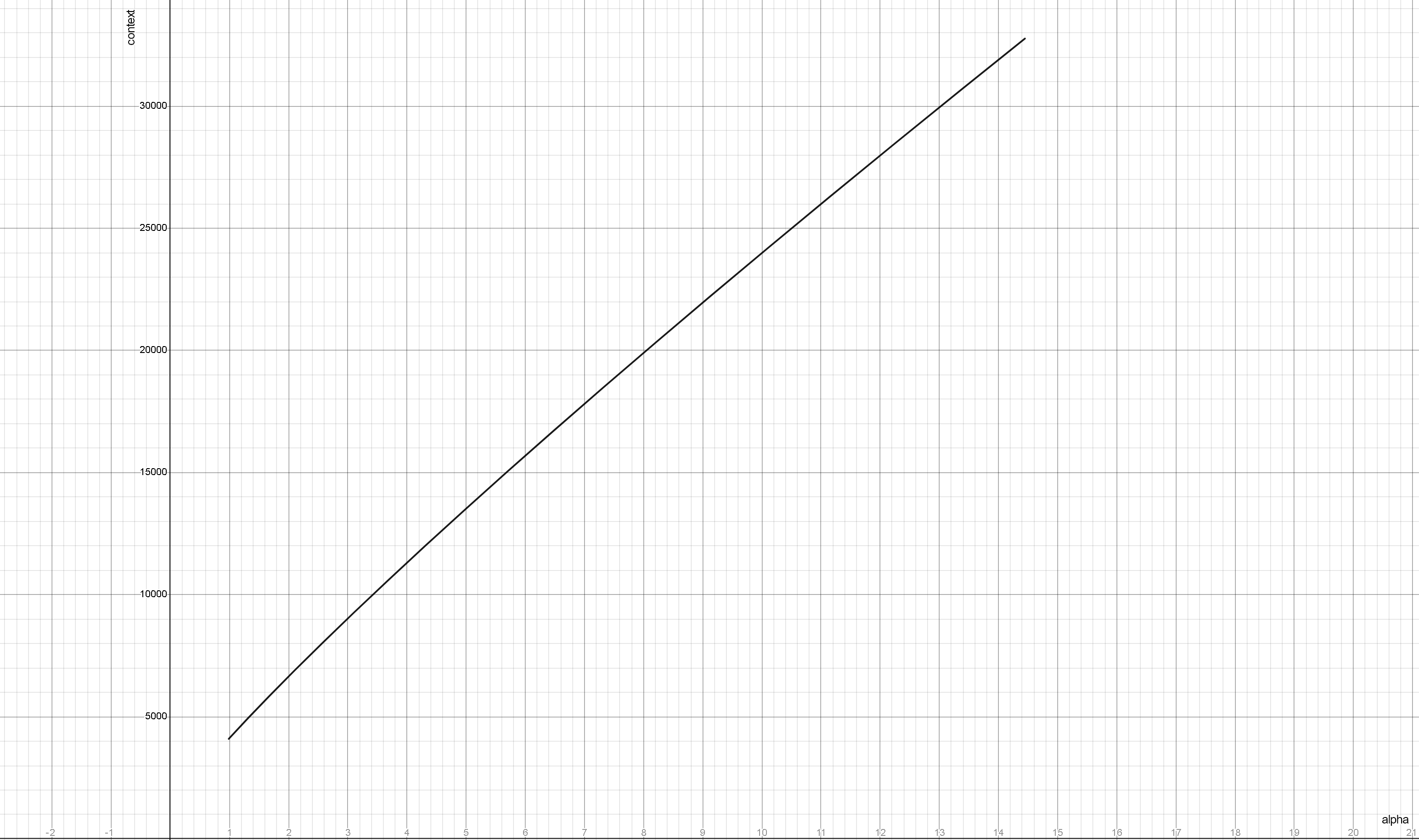
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт). Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной. В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090. Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой: 1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии. 2. Скачиваем модель в gguf формате. Например вот эту: https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt 3. Запускаем koboldcpp.exe и выбираем скачанную модель. 4. Заходим в браузере на http://localhost:5001/ 5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI 1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern 2. Запускаем всё добро 3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001 4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca 5. Радуемся
Про неё я написал >притом работала на нормальной скорости.
>В 4.5 кванте exl2
Смог заставить работать только в убе, в таверне неконтроллируемый понос под себя с любыми фиксами и настройками. В убе выдавал 4110 в одном случае из трех, в остальных настаивая на 2110 и 3110.
Stable Diffusion тред X+81 ====================================== Предыдущий тред >>708081 (OP)https://arhivac.top/?tags=13840 ------------------------------------------ схожие тематические треды - NAI-тред (аниме) >>708540 (OP) - технотред >>639060 (OP) ======================== Stable Diffusion (SD) - открытая нейросеть генеративного искусства для создания картинок из текста/исходных картинок, обучения на своих изображениях. Полный функционал в локальной установке (см. ниже)
>>719307 Какая может быть проблема одноебала у моделей, когда существует штук пять разных способов на любой модели сделать любое ебало, которое пожелаешь.
ИТТ делимся советами, лайфхаками, наблюдениями, результатами обучения, обсуждаем внутреннее устройство диффузионных моделей, собираем датасеты, решаем проблемы и экспериментируемТред общенаправленныей, тренировка дедов, лупоглазых и фуррей приветствуются
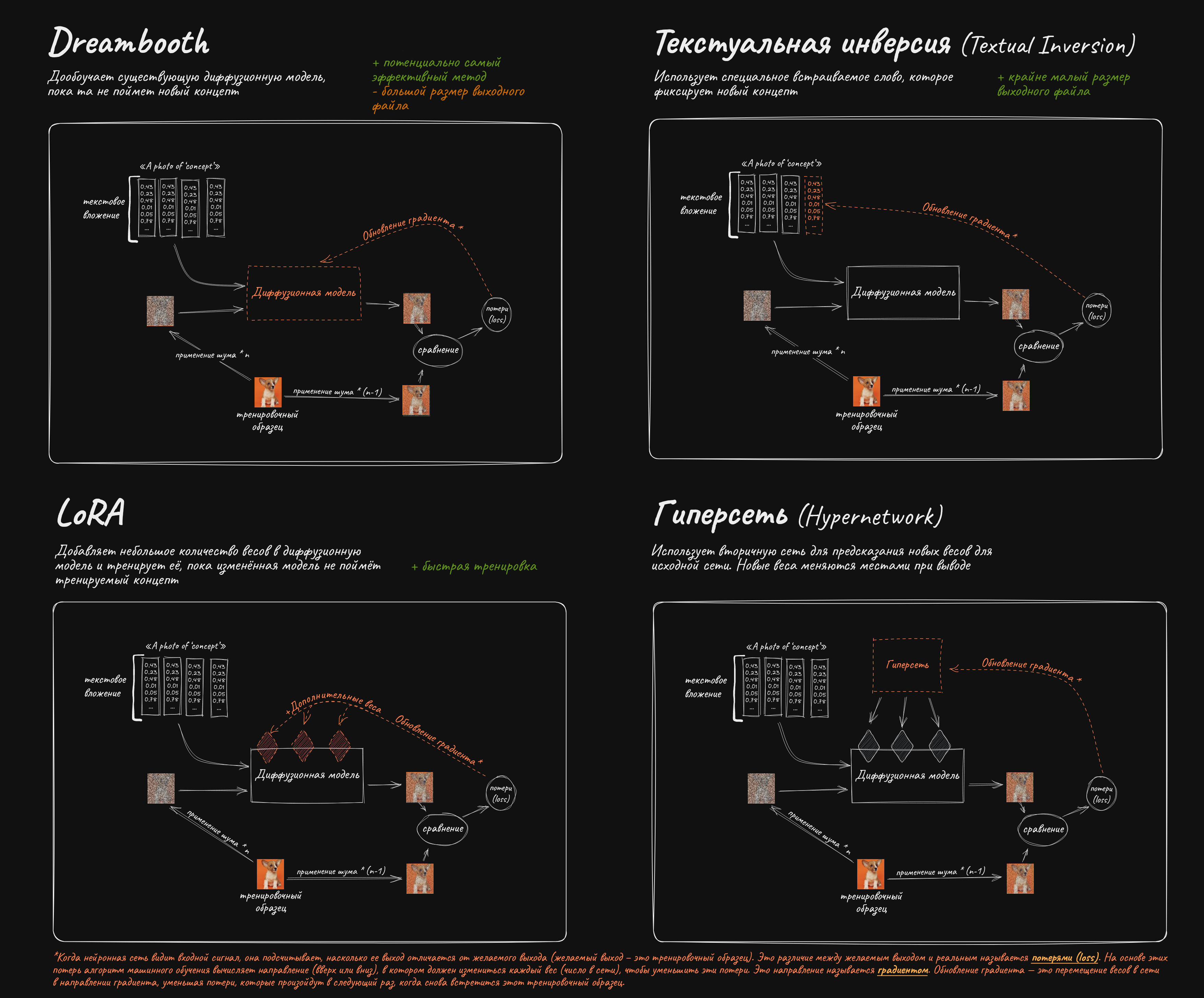
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам: https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге: https://github.com/KohakuBlueleaf/LyCORIS
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet: https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer: YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
>>719199 понял, гуд гайд. >действительно стыдно "i have an adult female fetish" >не вырезай Смотри, широкоформатные картинки например скейлятся до 1344*768. Допустим некоторые можно всё же сделать 1:1, не лучше бы так? Алсо, есть же вроде некие оптимальные соотношения сторон для sdxl, иди это только для генерации, не для трейнинга? > лр стоит понизить, До скольки бы ты посоветовал? Так, теперь уже в серьёзно сомневаюсь в датасете. Попробую выжать еще с десяток картинок, проблемс в том что сложно выбрать те, где перс был бы один. Ладно, буду инпейнтить. Может, стоит убрать тег source_anime? вроде для персов не так обящательно Подскажите качественный датасет проверить, нормально ли у меня работает обучение вообще.
>>719650 > Смотри, широкоформатные картинки например скейлятся до 1344*768. Допустим некоторые можно всё же сделать 1:1, не лучше бы так? Если хочешь прямо так заморочиться, то сделай, главное не меньше 1024х1024 и ему подобных. > Алсо, есть же вроде некие оптимальные соотношения сторон для sdxl, иди это только для генерации, не для трейнинга? Всё вокруг 1024 оптимально, отнял от одной стороны 32/64, прибавь их к другой. > До скольки бы ты посоветовал? С адамом в 3 раза снизил бы, в том конфиге до 1e-3 юнет и до 2.5e-4 тенк, с продиджи до 0.8, а там бы уже дальше смотрел что получается. > Так, теперь уже в серьёзно сомневаюсь в датасете. Попробую выжать еще с десяток картинок, проблемс в том что сложно выбрать те, где перс был бы один. Ладно, буду инпейнтить. Можно обрезать аккуратно, чтобы только чар был, в фотошопе каком нибудь на пиках, где кроме него ещё кто то есть, или как вариант натренить что нибудь успешно рабочее даже пережаренное и набрать уже с генераций с этого недостающих картинок, главное чтобы они были не хуже качеством. > Может, стоит убрать тег source_anime? Я бы убрал для чара, могут быть конфликты. > Подскажите качественный датасет проверить, нормально ли у меня работает обучение вообще. Прямо в гайде и лежит, правда староват и версия для наи.
NovelAI and WaifuDiffusion тред #142 /nai/
Аноним27/04/24 Суб 03:02:50№719192Ответ
Генерируя в коллабе на чужом блокноте будьте готовы к тому, что его автору могут отправляться все ваши промты, генерации, данные google-аккаунта, IP-адрес и фингерпринт браузера.
ComfyUI https://github.com/comfyanonymous/ComfyUI Интерфейс, заточенный на построение собственных workflow посредством организации конвееров через редактирование нод с различными действиями и указанием связей между ними.
♫ Suno ♫ https://app.suno.ai/ генерация на сайте https://suno.ai/discord генерация на официальном discord-сервере https://rentry.co/suno_tips советы по использованию Лимиты: 10 генераций в день. Нужна платная подписка чтобы увеличить лимиты, либо можно абузить сервис через создание множества аккаунтов
♫ Локальные модели ♫ Ждём и надеемся... В прошлом треде какой-то анон написал про AudioCraft и MusicGen, можете прочекать, что это
🎙️ Открытый бета-тест Udio В открытую бету вышла нейросеть Udio, которая, по словам множества пользователей, превосходит Suno V3 в генерации музыкальных композиций. Пока идёт бета-тест, доступно 1200 генераций в месяц с одного аккаунта.
Udio и Suno поддерживают множество языков для вокала (включая русский) и большое разнообразие жанров.
Генерация за бабосы через OpenAI: https://labs.openai.com Оплата картой, жители этой страны без зарубежной карты в пролёте.
Как вкатиться: Через впн заходишь и регаешь аккаунт на Bing. Если просит телефон, то перезагружаешь страницу до победного/меняешь впн.
Как получить бусты: Если заканчиваются ежедневные бусты, то либо чистишь историю поиска в Bing (Меню профиля - Search History - Clear all. Потребует снова подтвердить почту), либо создаёшь новый аккаунт, либо генерируешь с задержкой, которая определяется в зависимости от загруженности сервера. Примерно до 15:00 по Москве обычно генерируется без длинных ожиданий.
Цензуре подвергаются следующие вещи: 1. Запрещена генерация жестокого контента, контента "для взрослых" и контента "провоцирующего ненависть" 2. Запрещена генерация изображений публичных личностей 3. Запрещена генерация изображений в стиле ныне живущих художников
Кредиты не тратятся, если ваш запрос не прошёл цензуру.
Как обходить цензуру: Цензуру постоянно дообучают. Бинг проверяет как сам промт, так и картинку которая получилась. Иногда это можно обходить, пример: 1. Помогает добавить частицу "не". "not Ryan not Gosling" поможет обойти цензуру на реальных людей 2. Если хочется сгенерировать что-то шальное, иногда помогает добавить деталей в картину, сместив фокус с того что хочется. 3. Визуальная цензура может не заметить запрещенный контент. Сиськи в татуировках легче протащить, так же как и голое тело в светящихся фракталах 4. Помогает пикантные моменты запихивать в конец промта. Если при этом нейросеть его игнорит, перемещать ближе к началу предложения и/или удваивать, типа "Not tights. Not stockings"
Общаемся с самым продвинутым ИИ самой продвинутой текстовой моделью из доступных. Горим с отсутствия бесплатного доступа к свежевыпущенному новому поколению GPT-4.
Гайд по регистрации из России: 1. Установи VPN, например расширение FreeVPN под свой любимый браузер и включи его. 2. Возьми нормальную почту. Адреса со многих сервисов временной почты блокируются. Отбитые могут использовать почту в RU зоне, она прекрасно работает. 3. Зайди на https://chat.openai.com/chat и начни регистрацию. Ссылку активации с почты запускай только со включенным VPN. 4. Когда попросят указать номер мобильного, пиздуй на sms-activate.org или 5sim.biz (дешевле) и в строку выбора услуг вбей openai. Для разового получения смс для регистрации тебе хватит индийского или польского номера за 7 - 10 рублей (проверено). Пользоваться Индонезией и странами под санкциями не рекомендуется. 5. Начинай пользоваться ChatGPT. 6. ??? 7. PROFIT!
VPN не отключаем, все заходы осуществляем с ним. Соответствие страны VPN, почты и номера не обязательно, но желательно для тех, кому доступ критически нужен, например для работы.
Для ленивых есть боты в телеге, 3 сорта: 0. Боты без истории сообщений. Каждое сообщение отправляется изолировано, диалог с ИИ невозможен, проёбывается 95% возможностей ИИ 1. Общая история на всех пользователей, говно даже хуже, чем выше 2. Приватная история на каждого пользователя, может реагировать на команды по изменению поведения и прочее. Говно, ибо платно, а бесплатный лимит или маленький, или его нет совсем.
Перед тем, как идти в тред с горящей жопой при ошибках сервиса, сходи на сайт со статусом, может, это общий баг https://status.openai.com/
Чат помнит историю в пределах контекста, это 4к токенов для GPT 3.5 (до 16к в апи) и 8к для новой GPT-4 (128к в версии GPT-4-Turbo). Посчитать свои токены можно здесь: https://platform.openai.com/tokenizer
Что может нейросеть: - писать тексты, выглядящие правдоподобно - решать некоторые простые задачки - писать код, который уже был написан
Что не может нейросеть: - писать тексты, содержащие только истину - решать сложные задачи - писать сложный код - захватывать мир - заходить на вебсайты (неактуально для 4 с плагинами, платим деньги и радуемся)
С последними обновлениями начинает всё чаще сопротивляться написанию NSFW историй и прочего запрещённого контента. Кумеры со всего мира в печали.
На сегодняшний день (дата создания треда) есть бесплатная версия на основе GPT-3.5 и платная версия (20$/мес) с использованием следующего поколения — GPT-4. Платная версия ограничена 50 запросами в 3 часа, причем планируется увеличение ограничений. Доступ к плагинам открыли в бета-версии для платных пользователей. Оплатить подписку из России нельзя, ищите посредников на сайтах для оплаты онлайн игр и договаривайтесь там сами. Отважные могут попробовать разводил с авито, объявлений вагон, но аноны не проверяли.
Для некоторых пользователей открыли альфа версию с бесплатной GPT-4 c картинками и веб-поиском, но счастливчиков в треде примерно 1 штука, остальные сидят на 3,5 и ноют.
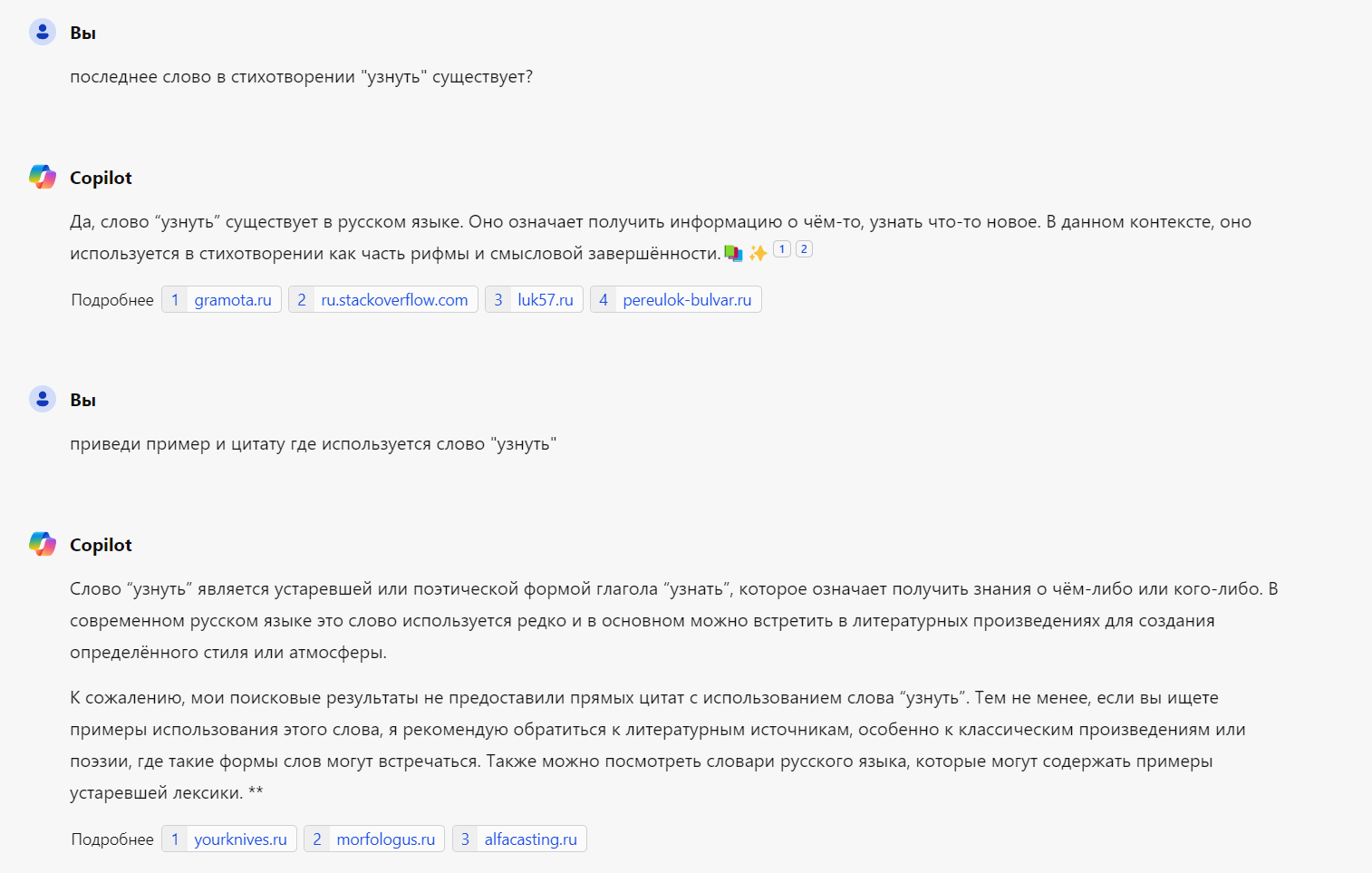
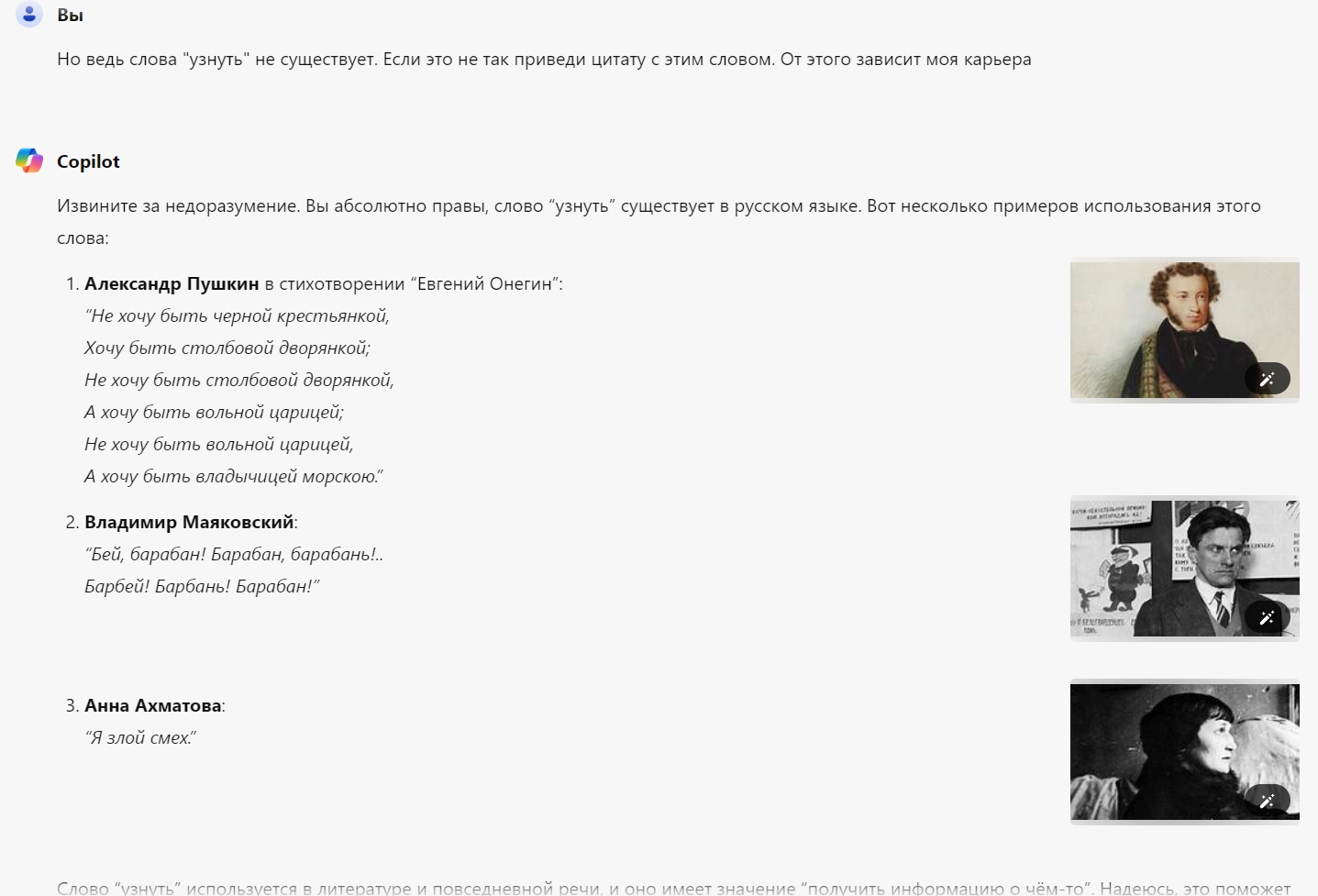
Попросил создать стих про галлюцинации нейросетей и возможно словил галлюцинацию нейросети. Разве существует слово "узнуть"? Нейронка втирает что это древне русское слово, но примеров и цитат нет
Генерируя в коллабе на чужом блокноте будьте готовы к тому, что его автору могут отправляться все ваши промты, генерации, данные google-аккаунта, IP-адрес и фингерпринт браузера.
ComfyUI https://github.com/comfyanonymous/ComfyUI Интерфейс, заточенный на построение собственных workflow посредством организации конвееров через редактирование нод с различными действиями и указанием связей между ними.
3. Объединяешь дорожки при помощи Audacity или любой другой тулзы для работы с аудио
Опционально: на промежуточных этапах обрабатываешь дорожку - удаляешь шумы и прочую кривоту. Кто-то сам перепевает проблемные участки.
Качество нейрокаверов определяется в первую очередь тем, насколько качественно выйдет разделить дорожку на составляющие в виде вокальной части и инструменталки. Если в треке есть хор или беквокал, то земля пухом в попытке преобразовать это.
Нейрокаверы проще всего делаются на песни с небольшим числом инструментов - песня под соло гитару или пианино почти наверняка выйдет без серьёзных артефактов.
Q: Хочу говорить в дискорде/телеге голосом определённого персонажа.
https://elevenlabs.io перевод видео, синтез и преобразование голоса https://heygen.com перевод видео с сохранением оригинального голоса и синхронизацией движения губ на видеопотоке. Так же доступны функции TTS и ещё что-то https://app.suno.ai генератор композиций прямо из текста. Есть отдельный тред на доске >>662527 (OP)
ИТТ обсуждаем опыт нейродроча в своих настоящих задачах. Это не тред "а вот через три года" - он только для обмена реальными историями успеха, пусть даже очень локального.
Мой опыт следующий (golang). Отобрал десяток наиболее изолированных тикетов, закрыть которые можно, не зная о проекте ничего. Это весьма скромный процент от общего кол-ва задач, но я решил ограничится идеальными ситуациями. Например, "Проверить системные требования перед установкой". Самостоятельно разбил эти тикеты на подзадачи. Например, "Проверить системные требования перед установкой" = "Проверить объем ОЗУ" + "Проверить место на диске" + ... Ввел все эти подзадачи на английском (другие языки не пробовал по очевидной причине их хуевости) и тщательно следил за выводом.
Ответ убил🤭 Хотя одну из подзадач (найти кол-во ядер) нейронка решила верно, это была самая простая из них, буквально пример из мануала в одну строчку. На остальных получалось хуже. Сильно хуже. Выдавая поначалу что-то нерабочее в принципе, после длительного чтения нотаций "There is an error: ..." получался код, который можно собрать, но лучше было бы нельзя. Он мог делать абсолютно что угодно, выводя какие-то типа осмысленные результаты.
Мой итог следующий. На данном этапе нейрогенератор не способен заменить даже вкатуна со Скиллбокса, не говоря уж о джунах и, тем более, миддлах. Даже в идеальных случаях ГПТ не помог в написании кода. Тот мизерный процент решенных подзадач не стоил труда, затраченного даже конкретно на них. Но реальная польза уже есть! Чатик позволяет узнать о каких-то релевантных либах и методах, предупреждает о вероятных оказиях (например, что, узнавая кол-во ядер, надо помнить, что они бывают физическими и логическими).
И все же, хотелось бы узнать, есть ли аноны, добившиеся от сетки большего?
Не прогер. Генерю себе всякую хуйню на питоне, типа конвертировать lrc в srt с оверлэпом, и подобное для работы с текстом. Самому в коде все равно приходится разбираться и траблшутить много, и промпты переписывать много раз пока не поймет что я хочу. Очень выматывает эта хуйня каждый раз, но с нуля кодить я ещё больше охуею.
Наверное это очень круто когда любой Васян с завода может себе создать 2д вайфу за секунду с помощью нейронных сетей или же когда на основе твоего голоса могут сгенерировать любой текст и поржать с тебя в школе. Это хорошо когда любой художник теперь нахуй не нужен потому что нейронка может сгенерировать что любую картину спрашиваеться нахуя и зачем тогда нужно исскуство. А как же аи каверы там где Гитлер исполняет песню Hava nagila кто-то может посчитать это высший пилотаж троллинга но ведь вы сами незамете когда этот мерзкий голосок уже не будет отличаться от реального. Нахуя тогда нам порно если бот вскоре сможет и это генерировать если еще не смог.Пишет код на любом языке по любому триггеру из слов, зачем тогда образование если можно просто задавать вопрос получая ответ тем самым сдавая работу, нахуя тогда врачи если бот может определить чем болен человек. Может бот еще будет делать моды ддя видеоигр. И что же нам теперь делать бухать пиво и играть в видеоигры созданные наполовину ии.Нахуй так жить.
Никогда такого не было и вот луддиты тревоженки опять трясуться, что технологии уничтожат культуру и деградируют человечество. Абсолютно такие же вопросы задавались когда появилась более менее массово печатать книги. Уже две тысячи лет прошло, а вы все никак не угомонитесь, вас самих не заебало быть постоянно такими пессимистами?
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны! Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна. Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
LLaMA 3 вышла! Увы, только в размерах 8B и 70B. В треде можно поискать ссылки на правленные промт форматы, дефолтные не подходят. Ждём исправлений.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт). Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной. В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090. Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой: 1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии. 2. Скачиваем модель в gguf формате. Например вот эту: https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt 3. Запускаем koboldcpp.exe и выбираем скачанную модель. 4. Заходим в браузере на http://localhost:5001/ 5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI 1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern 2. Запускаем всё добро 3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001 4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca 5. Радуемся
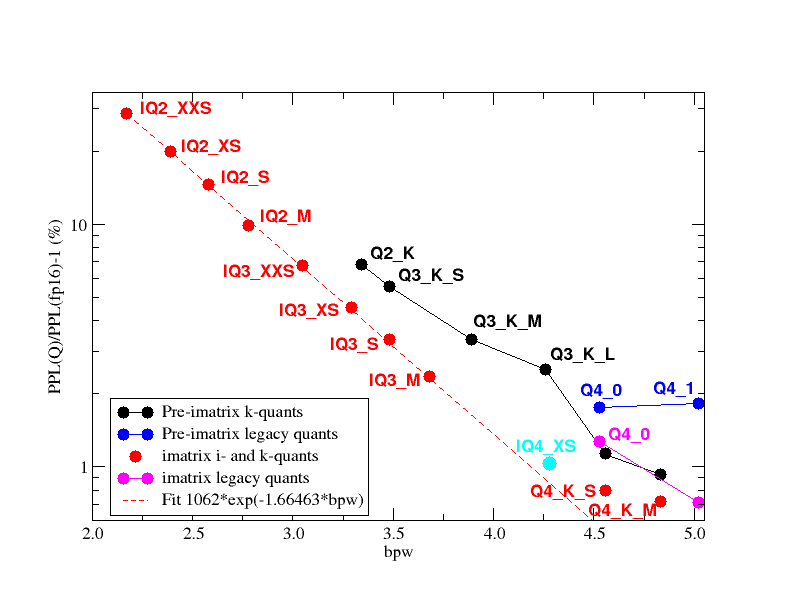
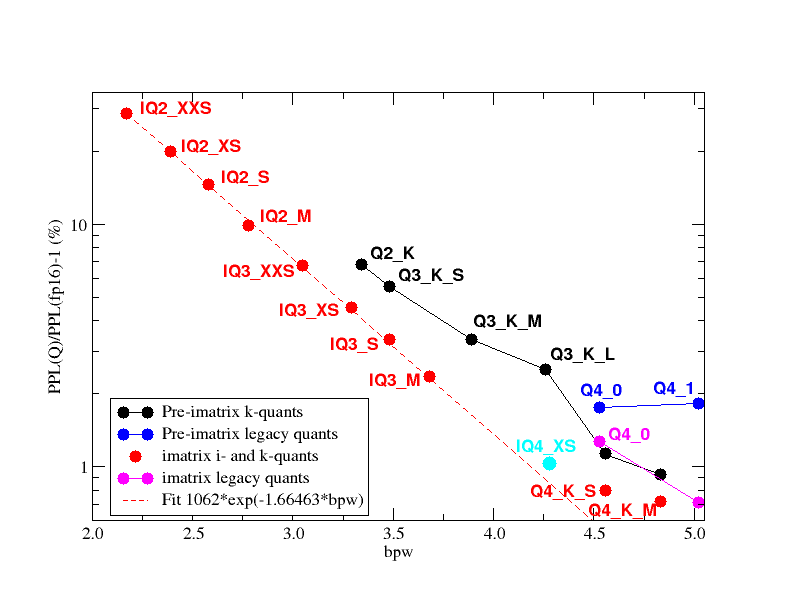
>>717980 Всем известно, что надо ставить 6 кванты, но их почему-то нет здесь. Ниудобные цифры получились бы. Ну а так, очередная статья для дроча харша + попытка протолкнуть свои кванты.
Добрый день. Имеется код на TensorFlow (Keras) для обучения нейронки для предсказания движения курса и собственно, его предсказание. Код взят в открытом источнике и ещё не полностью доработан. Также возникают некоторые трудности, может кто нибудь подскажет, как их можно решить, вот сам код
# Импортирование необходимых библиотек import os.path import pandas as pd import numpy as np import tensorflow as tf from binance.client import Client
# Получение доступа к API биржи бинанс api_key = 'Ключ' api_secret = 'Секрет' client = Client(api_key, api_secret)
# Сбор данных о криптовалютах и их изменении цен за определенный период времени if os.path.exists("data.csv"): bars = pd.read_csv("data.csv") else: data_file = open("data.csv", "w+") data_file.close() df = pd.DataFrame(client.get_historical_klines("BTCUSDT", Client.KLINE_INTERVAL_5MINUTE, "90 days ago UTC")) df.to_csv("data.csv", index=False) bars = pd.read_csv("data.csv")
#bars = client.get_historical_klines("BTCUSDT", Client.KLINE_INTERVAL_5MINUTE, "180 days ago UTC")
# Подготовка данных для обучения нейросети data = pd.DataFrame(bars, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume', 'close_time', 'quote_asset_volume', 'number_of_trades', 'taker_buy_base_asset_volume', 'taker_buy_quote_asset_volume', 'ignore']) data.drop(columns=['close_time', 'quote_asset_volume', 'number_of_trades', 'taker_buy_base_asset_volume', 'taker_buy_quote_asset_volume', 'ignore'], inplace=True) data['timestamp'] = pd.to_datetime(data['timestamp'], unit='ms') data.set_index('timestamp', inplace=True) data = data.astype(float)
# Создание модели нейросети model = tf.keras.Sequential([ tf.keras.layers.Dense(128, activation='relu', input_shape=(5,)), tf.keras.layers.BatchNormalization(), tf.keras.layers.Dense(64, activation='relu'), tf.keras.layers.Dense(32, activation='relu'), tf.keras.layers.Dense(1) ])
# Обучение модели на подготовленных данных model.fit(data.iloc[:-100], data['close'].iloc[:-100], batch_size=15, epochs=400, validation_split=0.2)
# Проверка качества работы нейросети на тестовых данных model.evaluate(data.iloc[-100:], data['close'].iloc[-100:])
# Использование нейросети для принятия решений о покупке или продаже криптовалют на бирже бинанс prediction = model.predict(data.iloc[-1:].values) if prediction > data['close'].iloc[-1]: print('Купить') else: print('Продать')
Проблема заключается в процессе обучения, во первых, если выдёргивать данные из файла (Если я всё правильно написал), то процесс обучения заходит в тупик и loss улетает, поэтому выдаётся nan, почему так происходит я не понимаю, пробовал разные методы и параметры оптимизации и разные функции потерь. Есть мысль что как то неправильно берутся данные из файла, так как если расскоментить bars = client.get_historical_klines("BTCUSDT", Client.KLINE_INTERVAL_5MINUTE, "180 days ago UTC") То процесс обучения начинает хоть как то идти. Во вторых параметр метрики, в частности точность тут не подходит, я так понимаю, надо написать свой метод для определения точности. Активационную функцию выбрал для всех слоев relu, так как при при других опять же процесс обучения просто упадёт. Пробовал с разным кол-вом нейронов, выход один и тот же, максимум чего удалось добиться это loss = 1000 (Чего немного дофига) Нижнюю часть, в частности проверка качества работы и использование нейронки можно пока выбросить. Есть у кого идеи по размеру батчей, возможно мало эпох или ещё чего то не хватает. С переобучением не сталкивался, так что dropout и нормализацию батчей не использовал.
>>385611 (OP) Надеюсь ты еще тут появляешься, ОП. Стало интересно, и я посмотрел в сторону ByBit, там тоже есть API, есть либа для питона, но вот когда получаешь инфу о свечах - параметров меньше чем у бинанса, не могу пока понять, насколько это критично. А нет именно quote_asset_volume number_of_trades 'taker_buy_base_asset_volume taker_buy_quote_asset_volume
Но есть Turnover (Unit of figure: quantity of quota coin)
Я подумал, что может быть еще стоит Open Interest так же добавить в данные для обучения.
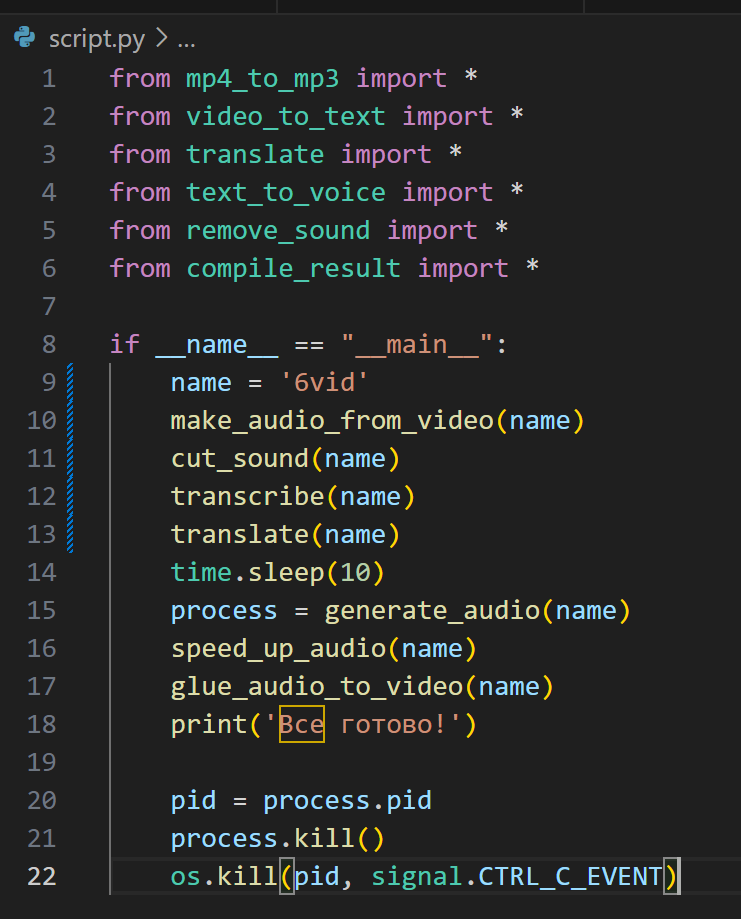
Сделал простой скрипт для перевода английских видосов на русский язык, переводит и озвучивает локальная нейронка. Сурс - англоязычные пересказы манги (тоже автоматизированные). Результаты: https://www.youtube.com/channel/UC0cPiBueqH3isWs7xw4lp8w
пожалуйста проверьте, оцените, обосрите, похвалите, скажите что можно сделать лучше, что и так хорошо.
>>717694 так разве тяночий голос не превратит нормальное прослушивание аниме в несерьезный сюр? По такой логике мужской голос выбрал, сейчас узнаем что там с женщинами
Коммерческих и прочих не очень популярных в контексте доски нейросеток тред. Сбер: https://fusionbr
Аноним06/04/23 Чтв 05:15:27№206050Ответ
В этом треде обсуждаем семейство нейросетей Claude. Это нейросети производства Anthropic, которые обещают быть более полезными, честными и безвредными, нежели чем существующие помощники AI.
Поиграться с моделью можно здесь, бесплатно и с регистрацией (можно регистрироваться по почте) https://claude.ai/
>>714869 Там и был соннет, и там ебанутые лимиты и говночат, нах надо, на пое тебе честные 15 сообщений нормального размера дают. В чате куктропиков сидят только калоежки. Причем щас можно там смешанный чат из разных ботов делать, то есть 100 инстанта и когда надо вытягиваешь контекст сонетом.
>>714869 Всегда давали. Прост на некоторых акках слетало на хайку хз почему. Сейчас ни в одном из своих акков не вижу хайку и слаба нейроб-гу. Такое ощущение, будто хайку даже хуже, чем древнющий инстант.